© University of Kent - Contact | Feedback | Legal | FOI | Cookies
- School of Computing ShowcaseVirtual Poster Fair
-
Welcome to the School of Computing's virtual poster fair
Scroll down through the list of projects and click on any project you would like to view. A larger version of the poster can be viewd by clicking on the poster thumbnail.
- C1 - Development of an Android App for Better Location Privacy Protection
-

May Ottoway, James Lawrence, Jiyeon Jung
Supervised by: Professor Li Shujun
Project description
The project aim is to make users more aware of the location data they are sharing to companies and organisations with the main focus on what location data Google collects from users. The app is designed to easily show how secure your Google account information is in relation to how your location data is shared. In a constantly connected world, Google has become an intrinsic part of daily online life. Google collects your locations, your documents, your passwords, your email, and much more. By ranking and giving simple but actionable advice on securing your account, targeted at specific demographics and user groups, ACCEPT has been built to give more control over your digital life. The goal is not to make users completely stop sharing their data, but to consider the trade-offs in sharing different types of data. Showing messaging and summaries of data found are essential to guide users on how they can change their behaviours.
Results
We have created a mobile application ACCEPT. ACCEPT works by sorting users into various categories. These categories are based on the factors: willingness to take security risks, lifestyle, and personal security requirements. The categories of users are sorted into are: Cyber Risk Takers, Physical Risk Taker, Transport Innovators, Risk Abstainers. Each group has different needs for security and has varying levels of security and privacy requirements. The app gently reminds the user to check their security settings by numerically displaying a value based on the user’s current security level. We have worked with researchers to create messaging and nudging that results in the most impact when ensuring users review their data-sharing habits. After using the app for a few days, users can view the data that the app has found that Google has collected in an easy to digest report including advice on how to move forward.
- C2 - TimeMap
-
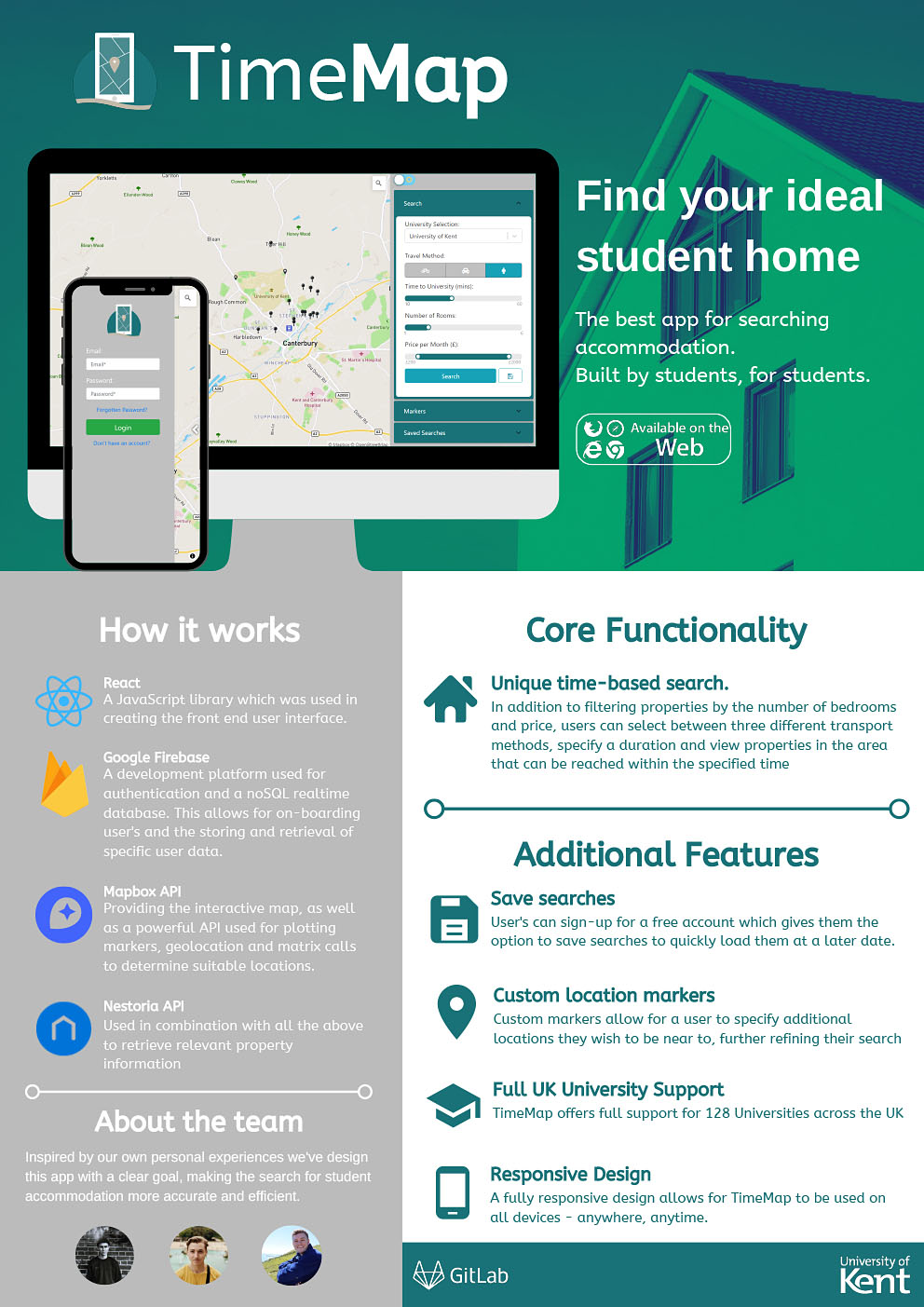
Isaac Williamson, Callum Mardle, Charlie Cook
Supervised by: Radu Grigore
Project description
Current property search tools only allow users to search for properties based on the distance from a single geographical area, in our own experience we have found this to be extremely limiting when searching for university accommodation. A much greater concern for students is the length of time it will take to get from their accommodation to their university campus.
Our project offers a more efficient property search tool for students, allowing them to search by specifying the duration of time they wish to be from their university by either walking, cycling or driving. Additionally, there are often secondary points of interest (shops, gyms, nightlife etc.) that students wish to be near to, therefore our project provides custom markers for users to place on the map, alongside a duration for each. This further refines their search results and supports them in finding their ideal accommodation.
Results
Our solution provides a responsive web application built with JavaScript library React. Users search for properties by selecting the time they wish to be from their selected university (128 UK universities supported), number of bedrooms and price. Our solution uses housing API Nestoria to return properties in the area that match the given parameters and results are passed to navigation API Mapbox. Calls are made to Mapbox, returning the duration from the university to each property and those that are within the given time requirements are presented on an interactive map. Users can add additional locations they wish to be near, which are appended to the matrix calls and only properties that match all requirements are displayed. Users can create a profile which allows them to save and load searches - both the user profiles and saved searches are facilitated using authentication and real-time databases on Google’s Firebase platform.
- C3 - Cyclo-Net
-
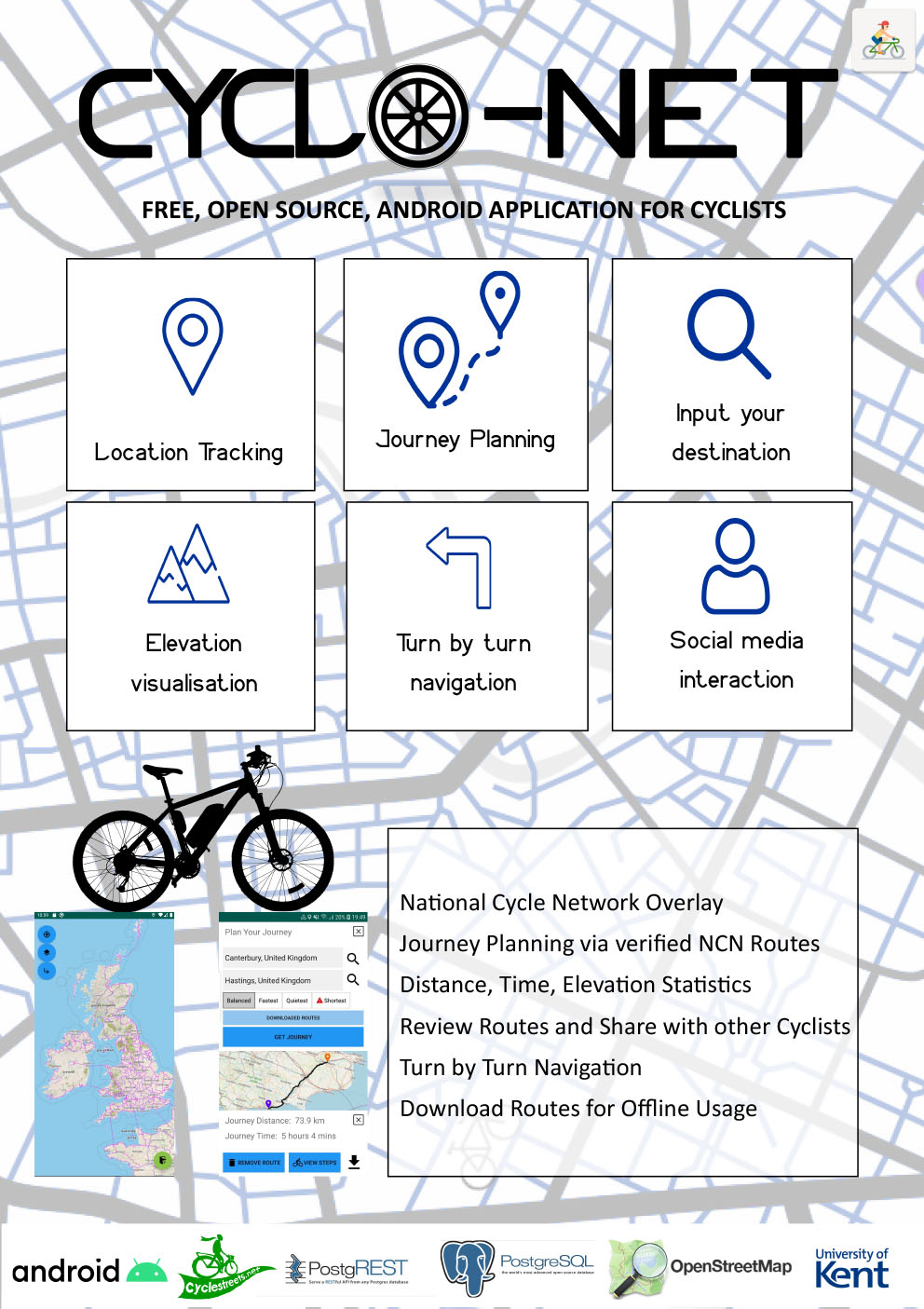
Luke Davis, Gabriel Razzouk, Gursimran Khalsa, Bradley Rouse
Supervised by: Peter Rodgers
Project description
Cyclo-Net is a free, open-source Android mapping application for cyclists. It provides route planning, user location tracking, turn-by-turn navigation and other basic navigation functionality. Cyclo-Net tailors this functionality towards cyclists, with the route planning adhering to verified cycling routes, to ensure that the cyclist does not find themselves in undesirable areas. Cyclists are also able to choose between various routing profiles, such as faster routes or more quiet ones. The route is supplemented by other useful information for cyclists, such as elevation, user tracking and a layer showing the National Cycling Network map. The application provides the ability to download routes for offline usage, particularly useful for routes with poor network reception. The app also intends to implement social media functionality, with the ability to provide feedback on routes. User analytics will provide useful information, such as the total distance travelled and average speed of the user.
Results
The application currently provides navigation functionality, with the ability to generate a route from one location to another. The user can tailor this route by selecting the routing profile they desire, such as quietest or fastest. The route itself provides details such as each street along the route, the total time to travel the route and the total distance. Routing is provided by an external API (CycleStreets) who have designed their routing algorithm around cycling routes. The user can download this route for offline access. User tracking functionality has been implemented in the form of displaying the user’s location on the map and panning to it. A layer providing all the National Cycling Routes has been added to the app, which can be toggled on or off. Social media implementation includes the ability to log in uniquely and provide reviews for certain routes.
- C4 - FreeLancer
-

Bailey English, Hashim Ali, Nathan Orsmond
Supervised by: Stephen Kell
Project description
The purpose of our project is to create a web application which enables freelancers to connect with the clients. When posting a job, it should be simple and easy. With FreeLancer, a job can be created with few specific details and if a freelance worker is interested, they can message asking for more details. Messages will be filtered with a machine learning based spam detection algorithm. Each profile will have their own section to showcase their achievements, abilities and the projects they have and are currently working on. Spam prevention is also a key feature of the product so someone can't barrage the job posting in hopes of having a better shot of securing the job.
Results
We have created a web application which allows freelancers and clients to register an account and login to view their own personalised dashboard. From there the freelancers can view all the posted projects as well as view the projects they have already accepted to work on. Clients can post projects and supply relevant descriptions to enable them to find the perfect freelancers to complete the required task.
- C5 - Police Database System
-

Thomas Bestwick, Alex Truman, Forash Miah, Ross Wickenden
Supervised by: Peter Rodgers
Project description
Our project is a Police database system used for storing evidence securely. It allows police officers to create evidence to do with a case on their mobile phone and view evidence that is already stored in the database, making it much more convenient for the officers rather than only being able to do it from a terminal. For security purposes the Evidence is only able to be approved/edited by the evidence custodian on the main terminal in the police station. This reduces the risk of phones being stolen and evidence being tampered with. Our android app contains much more basic functionality in comparison to our website as the android app is more for convenience. We developed this concept in hope that it would help boost the security around evidence storage and reduce evidence tampering while also reducing paper usage by switching from the paper format to this electronic one.
Results
The core system of the web application is implemented as it allows the evidence custodian to approve evidence, search the evidence database and keep an eye on what is being changed via a log function. The android application also has limited access as intended and can be used to submit an evidence form while also allowing the user to view their submitted evidence and waiting approval. We have implemented a wide range of security features to keep both applications secure like secondary authentication encoded into the Java, AES-256 encryption in the database, re-password entering for sensitive tasks in the main web and auto disconnect functions on both applications. The log implementation on the web application will also keep us informed as to who and when someone has made a change to the system.
Overall our systems have met our specifications and include a wide range of security features as intended.
- C6 - A Platform of Joy
-

Leigham Curtis, Logan Dean-Edwards, Sophie Friell
Supervised by: Sally Fincher
Project Description
We all know that waiting for a train is boring and repetitive, and this has been reinforced through our research and interviews with train passengers. People waiting for a train use their mobile phone as a means of distraction, and our research indicates that getting people off their phones would be a near impossible task. Using a Design Thinking approach, our project focuses on passengers at train stations and how we could possibly bring joy to UK platforms. Six months of research has allowed us to collect insights first-hand from staff, passengers and secondary research to understand user needs and identify ways in which we could create a platform of joy.
Results
Research shows that joy is contagious and unexpected (Fetell Lee, 2018). Our project has developed into a functional prototype intended to bring joy to commuters, known as Joy-Seekers, through their participation in daily challenges that utilise the train station environment. We have developed four interactions. Joy-Spotting encourages passengers to look up from their phones and capture what is around them. Joy-Tuning allows users to interact with a physical jukebox on the train platform to unlock joy through music. Joy-Noting allows users to share moments of joy they have spotted around the station through micro-stories. Joy-Collaboration allows users to connect with fellow passengers and work together by agreeing on a description of an image, obtained from Joy-Spotting. These interactions perfectly capture our findings. The prototype also offers surprises, from hidden features to temporary challenges introduced by train staff when train delays or issues occur.
Lee, I. (2018). Where joy hides and how to find it. [online] Ted.com. Available at: https://www.ted.com/talks/ingrid_fetell_lee_where_joy_hides_and_how_to_find_it [Accessed 25 Feb. 2020]
- C7 - UKC Maps
-

Toby James, Harold Nash, Bradley Williams, Ezra Wilton
Supervised by: Stephen Kell
Project description
The aim of our project was to create a set of functional maps of the university and university buildings that could be used for navigation/displaying room information. We decided the most efficient & user-friendly way to do this would be by hand-drawing a set of SVG maps in Inkscape and then manipulating these base maps with Javascript, PHP, Python & CSS as SVG uses the XML definition and is easily manipulated. The main functionality of the site would come from interacting with the interior maps so users may find out detailed information regarding different rooms and locations. We aspired to add a pathfinding feature to the maps, allowing a user to specify a location they would like to reach with our pathing algorithm showing the shortest path to that destination. We began the project by getting comfortable with SVGs and Inkscape.
Results
As planned we created a detailed, good looking exterior map of the campus with the ability to interact with the maps (panning, zooming, etc) and click into buildings to view their interiors or to pull up a summary of the buildings and related information in a side-bar menu. We also added the ability for the user to create accounts, sync their timetables with the site & add deadlines. We created a database to allow us to store staff information, room information, user logins, etc alongside an API which allows us to access this data. This also allowed us to implement a working search system for the website, allowing a user to query the site and find specific rooms, buildings alongside their occupants (such as which staff members reside in which office). We have also implemented a pathfinding feature which allows a user to show paths between elected buildings/rooms.
- C8 - The Seeker
-

Gabrielle Dompreh, Yasin Nathani, Emmanuel Salami, Eldad Owusu
Supervised by: Dominique Chu
Project description
The market for an application that prevents an individual from losing their item is limited. The notion of misplacing or forgetting an item somewhere is not an uncommon occurrence to this world. For example, statistics show that the average person loses more than 3000 possessions in their lifetime – this can include objects such as pens, keys and many more. Our project aims to solve this issue by creating an app that allows users to know when their item is not near them. The concept of Bluetooth Low Energy (BLE) will be applied to our development process which will require users to have a Bluetooth mobile device to use this application. A BLE beacon will be used as our hardware to notify the user when they are not near their item. Our proposed solution ensures this because as soon as a user of this application reaches 10 metres without their item in close approximation, our BLE beacon will start beeping to make them aware of the situation.
Results
The application meets the proposed user requirements documented during the planning stage. The user can now establish a connection with the BLE device. This establishment is confirmed by an alert from the BLE beacon. An individual can now use ‘The Seeker’ to be informed of the items which are not within their sight. The development process was achieved by using the ReactiveXAndroidBLE library to establish protocols such as Scanning and Connecting. This library provided us with the ability to manipulate the RSSI value (the distance) to create a sound alert when the individual is not near their item. Furthermore, it facilitated the procedure of executing complicated APIs such as the ‘Observable’ interface. This interface enabled a manageable implementation because it allowed us to execute multiple instructions concurrently. For example, rather than calling on a single method, ReactiveX allowed us to define a mechanism for retrieving and altering the data (i.e. Scanning/Connecting), in the form of an ‘Observable’. This then subscribes an observer to respond to its releases whenever they are ready. Users of this app will need an Android device which supports Bluetooth 4.0 or above.
- C9 - Virtual Receptionist
-
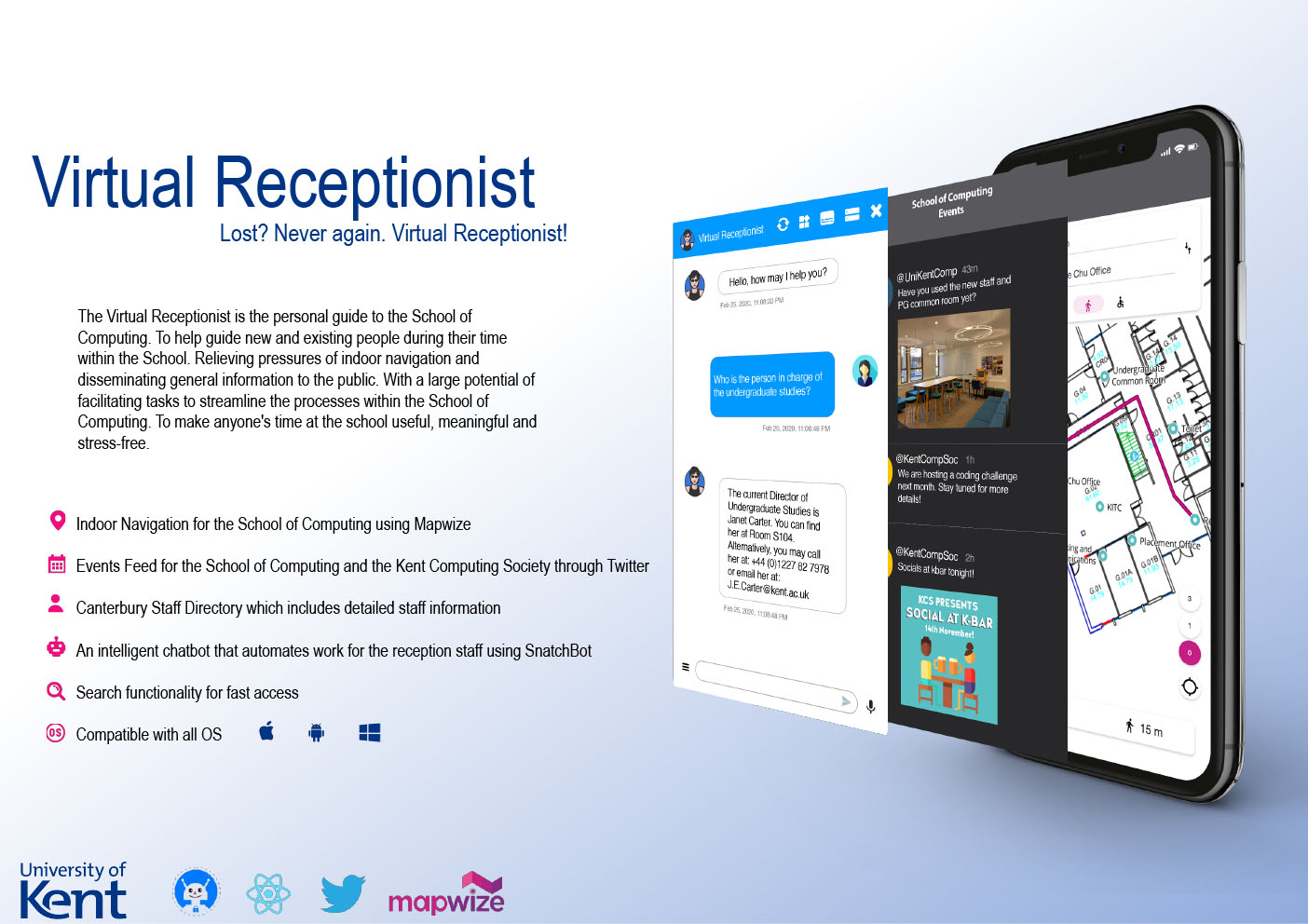
Anne-Nicole Kasilag, Chelsea Osakwe, Gurleen Vasir, Nun Srijae, Shirley Ale
Supervised by: Ian Utting
Project description
The project aim was to create a Virtual Receptionist application. The term “Virtual Receptionist” is quite broad. We decided to focus on a particular aspect of this term and correlate it to the main issue that the School of Computing has – Navigation. The School of Computing has architectural complexity which makes it hard to navigate. Our project will minimize and resolve that issue in some aspects. Our main features are as follows:
- Indoor Navigation for the School of Computing
- Twitter Feed for the School of Computing and the Kent Computing Society
- Canterbury Staff Directory, which includes information of each staff
- An intelligent chatbot with the potential to automate work for the reception staff
- Search functionality for fast access (i.e. staff information)
Results
In our findings we have discovered limitations that aren’t within our control and subsequently had to abandon some features and find workarounds for others. These limitations ranged from GDPR to the subscription services used for indoor navigation. The current impact for this application is to provide flexible guidance and accessible routes for people in unknown building complexes using Wi-Fi localisation. The potential impact for the School of Computing is the automation of services that the current system does manually i.e. module changes, seminar changes, instant notification of seminars/lectures clashes, and lecturer’s in-office availability etc. In our further development we would need to establish a tech stack that accommodates the different services that the School of Computing currently has to create these potential features. In conclusion, we have met the objectives that we agreed on within the limitations we discovered during the development phase.
- C10 - Chataholic
-
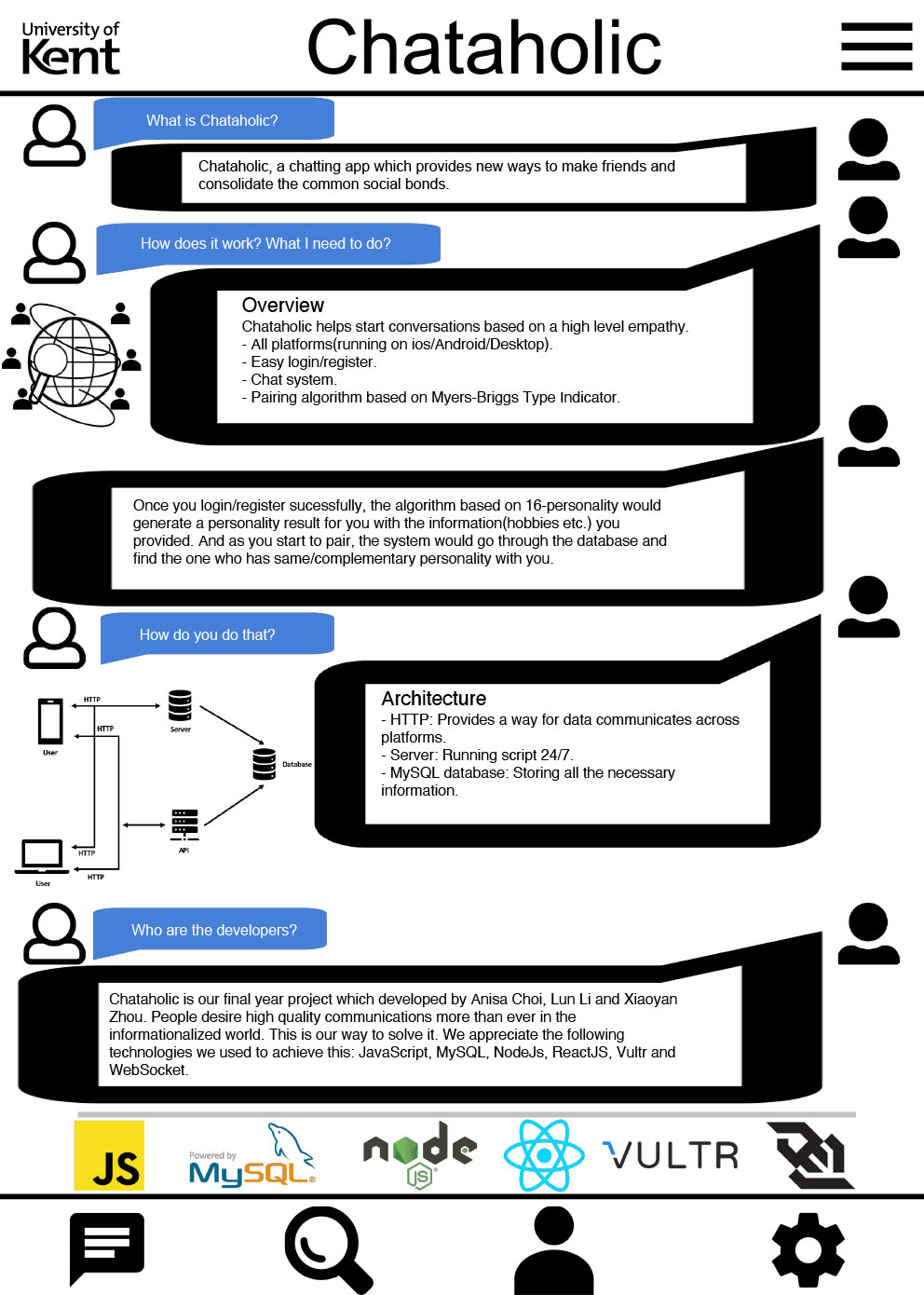
Kakei Choi, Lun Li, Xiaoyan Zhou
Supervised by: Olaf Chitil
Project description
The design of our apps aimed to build a Personality-Based Real-Time Dating (PBRTD) web-based social application that can pair people according to their results of personality tests and other interests.
By using a pairing algorithm, “Chataholic” will quickly pair two users based on the information collected from user profiles. The architecture will be consisted of a cross-platform application and an instant messaging system that communicating via a central API(Websocket) and the main framework we choose is ReactJS, for backend we are using nodeJS and for the central server we are using a virtual private server (VPS) from Vultr. VPS are small servers which isolated on a physical server. And it can be restarted independently and has its own root access, IP address, memory, etc. The function we will have is pairing users when user request, instance messaging system, authentication, modify the user profile and account details, pairing users and modify friend list, password changed, etc. The pairing algorithm will pair two users by computing the similarity between them. Convert the information from user profile and to a computable variable and use this variable as a parameter to find out a list of other potential matched users from the database, then randomly pick a user from the list.
Results
As planned, our project’s purpose is to perform a complete web chat application with a server and enable the users to seamlessly communicate with each other. The primary requirement of Chataholic is to provide a mechanism for Online chatting at a small scale. The user interface is easy to navigate, understand and use. Since it is based on web, the application will be available to use and when required. In the current state, our app is capable of authentication, sending messages, modifying users’ profile and it is runnable on the localhost. We are dedicated to improving it and deploy it to the server to illustrate a more complete version in the poster fair.
- C11 - Exploring Potential Security Issues with Drones to Combat Illegal Drone Activities
-
James Pearson, Josh Moffatt, Josh Konyk and Neelan Thuraisingham
Supervised by: Budi Arief
Project description
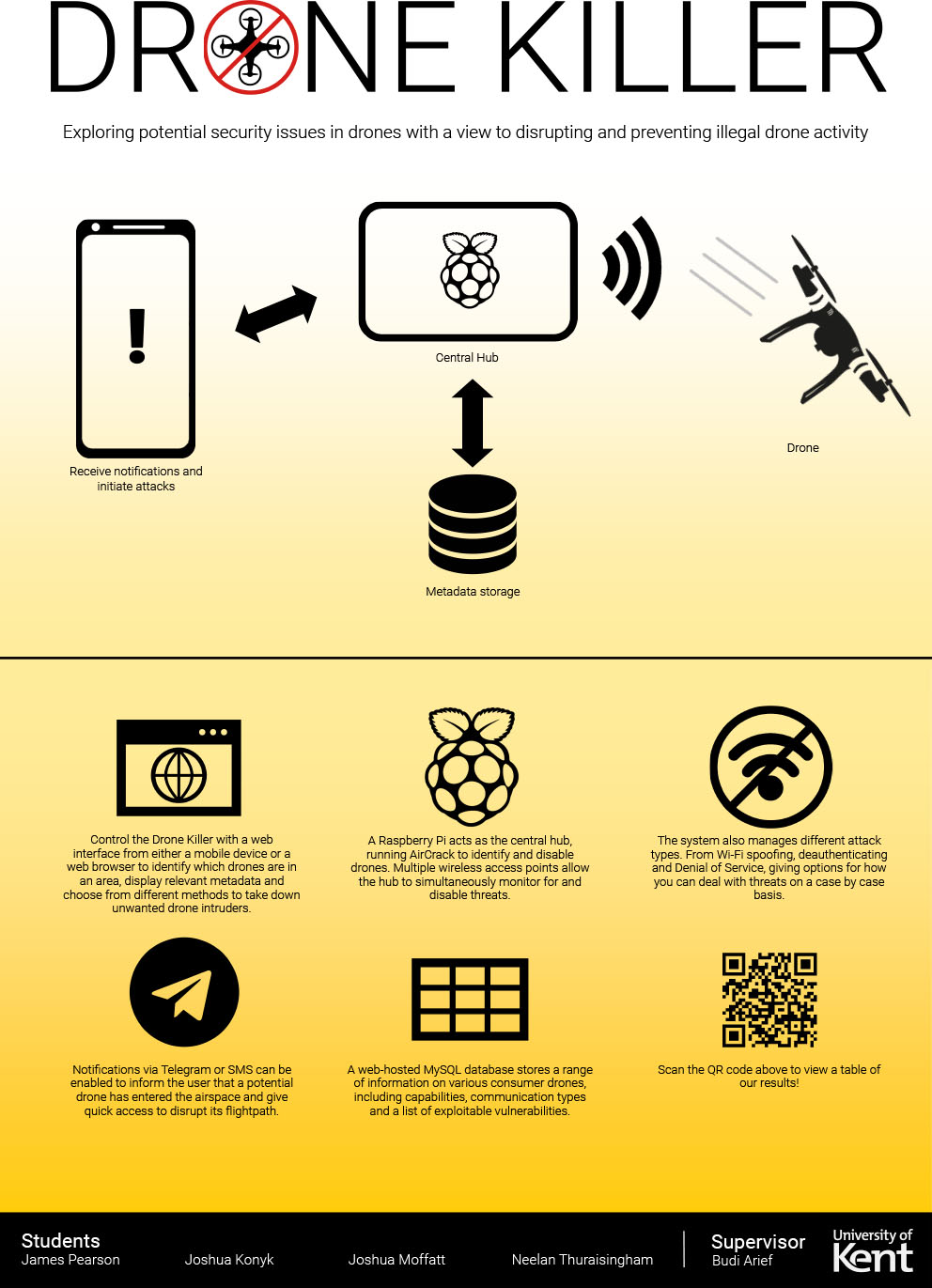
As drones get cheaper and easier to fly, they are becoming increasingly popular with hobbyists and commercial pilots, however they also have the potential to cause mass disruption. In December 2018 around 1000 flights were disrupted at Gatwick Airport because of 92 credible drone sightings around the airport, but the police and army were unable to detect any drones in the area and there was no anti-drone system in place.
Various groups have been working to address this problem for a while. Brute force methods of taking down drones, such as ballistic weapons, lasers, or using other drones to catch the intruding drone have been suggested as a means of preventing intrusions in controlled airspaces; however these approaches are not ideal as they could disrupt equipment or cause unnecessary damage to their surroundings.
This paper explores possible non-destructive ways of safely taking down drones and gathering metadata about them. This information would allow the relevant authorities to identify unauthorised unmanned aerial vehicles and their operators, then safely ground those specific drones while avoiding widespread disruption to the operation of other nearby devices.
This has been done by examining a number of drones available on the market today, inspecting the control data they were transmitting and receiving, decompiling the apps used to control the drones and disassembling the drones themselves to gain a better understanding of how they work. The protocols the devices used were also examined, like Wi-Fi and HTTP servers, to look at potential vulnerabilities here.
Wi-Fi enabled drones were found to be vulnerable to a few different attacks, although they were all susceptible to deauthentication attacks which could instantly ground some models and disable the camera on others. In the future, further research could be done to look at attacks which could disable non-Wi-Fi enabled drones.
- C12 - Smart Vision Guard
-
Zeshan Hossein Ghayoomi, Muhammad Amhan, Emil Ivanov, Rajaul Karim
Supervised by: David. J Barnes
Project description
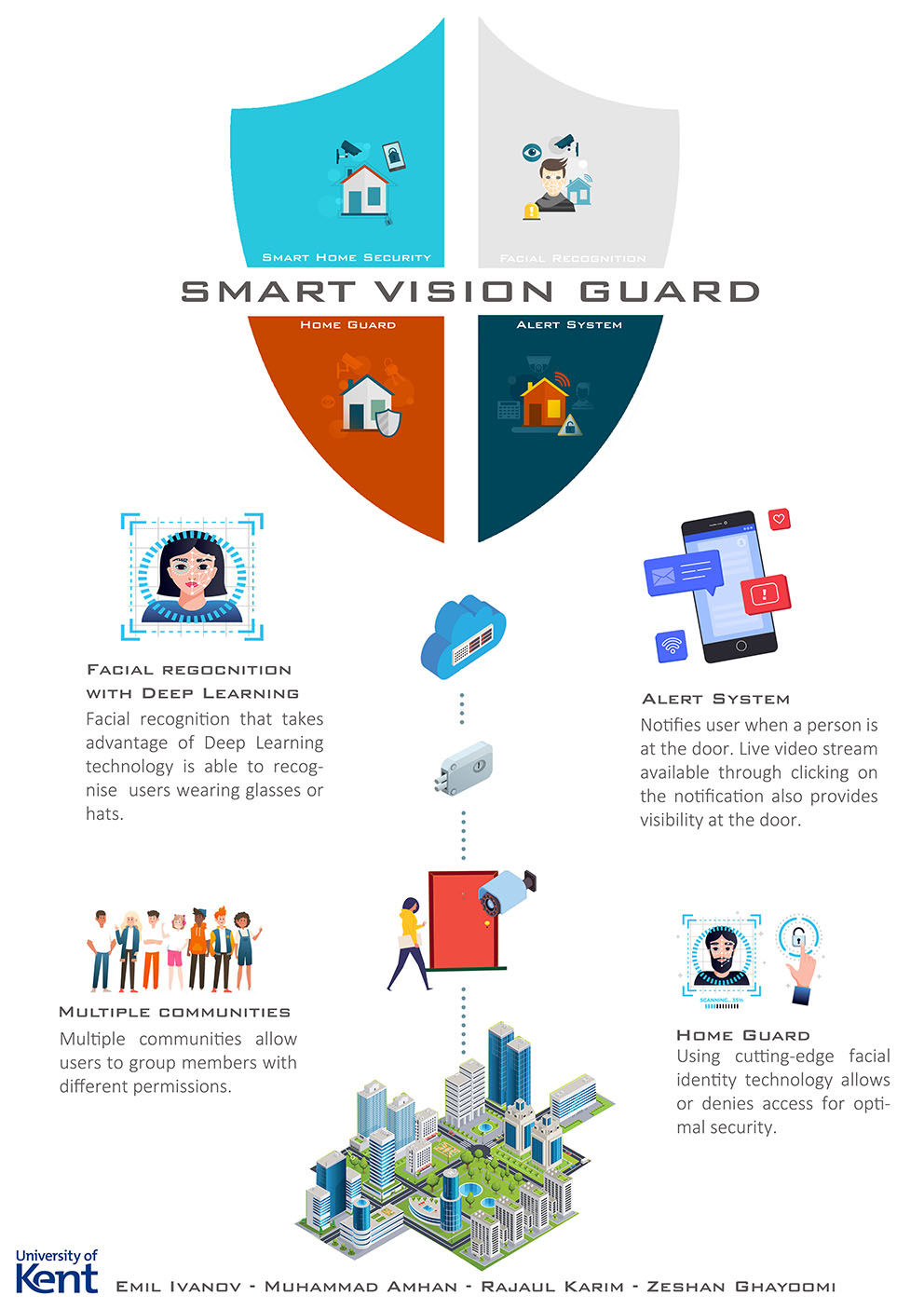
(SVG) Smart Vision Guard is a device that allows users to have keyless entry into facilities. The goal of the project was to build a camera device with facial recognition capabilities that can detect and recognise faces and unlock the door without the use of a key.
As part of this project, a cross platform mobile app for Android/iOS is also developed to allow the users to manage and customise the device according to their needs. To allow the mobile app and facial recognition to talk to each other, we have developed a sophisticated REST API that handles all the HTTPS requests back and forth between the mobile app and the facial recognition service.
Results
We have developed three different APIs and made use of Azure cloud services. All communications go through our core data API and utilized to feed our mobile app and other services such as the recognizer.
Users can create several communities, and each community has settings that apply to all its members. For example, one community may have escalated privileges than another, such as “automatic access” which results in giving its members access to a facility when they’re recognized. To achieve this, a user must add members’ information, including three pictures of each member. The pictures will be classified via our classifier API. Members will be recognized next time they arrive and greeted with a welcome message. The recognizer will take actions according to the community settings that they belong to.
Furthermore, a community may have push notifications enabled wherein anyone detected by the recognizer will trigger a notification being sent to the user’ phone.
SVG is also equipped with a feature giving users a live video feed, with multiple options such as live intercom to speak with the person, or the ability to grant remote access via our lock API.
- C13 - Adaptive Neural Network Environment (AI Video Game Director)
-

Nicholas Salter, Samuel Learmouth, Hoby Crittenden, Jordan Barber
Supervised by: Dominique Chu
Project description
An adaptive video game that uses a mixture of neural networks and genetic algorithms to learn how to scare the user. Using an artificial intelligence that detects how scared the user is from inputs given, the AI slowly learns which fears in its list are most effective to provide a tense and fun experience for the player. This game will be determining how much time will be taken between each fear being triggered and what specific fear to use through a fitness system and category based on previous experiences. It will learn through a constant feedback loop, taking the players reaction, quantifying it, and then feeding that to the AI system. The game itself is set in a hospital during a disease outbreak, the player has to battle with staying awake using means available to them, while avoiding obstacles and AI provided stimuli. The goal is to create a vaccine for the disease and escape.
Results
The base game was built within Unity where we manually coded the scripts pertaining to interaction and level design all done using C# and blender. The AI works based on two systems, the Time AI and the Fear AI. They both use biased randomness when choosing their respective components for the AI, which are then improved by monitoring the user’s reactions, and generating a fitness. These are called by the Fear Manager which will implement the fear into the game after it receives the necessary information from the AI systems. We monitor the users in game movement and mouse position in order to generate a fitness to train the AI system. Using these four systems we have achieved a learning feedback loop, which was our original goal. We managed to also create an entertaining narrative and gameplay surrounding the AI to make it more immersive.
- C14 - Uproar: A Mobile Platform for Ticket Ecommerce
-

Angus Clinch, Sam Donnelly, Tatenda Nyoni
Supervised by: Ian Utting
Project description
Uproar is an event management application targeted at university societies. The application provides a way to create events, manage tickets and authenticate users. Event managers can use the built-in barcode scanner to check customer’s tickets at the door. University of Kent students can use their student accounts to authenticate with the application and societies can easily manage both Kent only events and events for the general public. Uproar manages ticket sales and resales easily by giving users the opportunity to sell their tickets to each other second hand. The platform uses an APi to automatically generate a new barcode for the new ticket holder to prevent ticket duplication issues.
Societies can create and manage events better with a space to upload files for their members to view, automatic email list generation and a society question page where members can ask questions to the society leaders. Society leaders can easily manage committee members and transition the society to the next group of leaders when the year comes to an end.
Venues have access to analytical tools which include, demographic breakdowns, ticket sales data and specific user interests.
Results
The application has all the core features that we set out to achieve, with ticket, event and social management in place. Barcode generation and scanning work with Android and IOS devices when a workflow is adhered to but needs polishing to iron out some bugs. Initial tests with society leaders were very positive, but we are yet to use the application with a control group.
Single sign-on with the University of Kent SAML service is not working but single sign-on with an external SAML provider works well and provides one of the two current authentication methods. General public sign-on is working and the system is able to differentiate between the two groups and limit events to specific groups of people.
File uploads and email list generation are complete and work well for events with University of Kent students only but there is still work to do before this works with general population users. The society question functionality is still in progress.
- C15 - Commute TimeMap
-

Cameron Bamford
Supervised by: Radu Grigore
Project description
The aim of the project is to display a map showing the area the user could commute from given a destination and maximum transit time. The destination would be limited to within the UK, due to the availability of transit data. The user would need to be able to select a location they wanted to travel to, by inputting a postcode or nearby town, or dragging a marker on a map. They would also need to provide the maximum time they wanted to take on their commute. The result would be a map, showing their destination and the area they could travel to on public transport within the given time.
Results
The project renders a map showing a close estimate of where the user could commute from without taking longer than the given time. It allows for multiple forms of location input, such as postcodes, towns or streets, as well as finer adjustments to the destination marker.
The area showing commute radius is created using a combination of information from the Department of Transport (bus stop and rail station locations) and requests made to the Bing API. The project combines these sources into a grid of points with accompanying transit times, and generates an overlay on an Open Street Maps tileset, merging the points together by estimating walking distances in order to create a single interconnected space.
The commute area it shows is accurate, given reasonable transport links in the commute area. It estimates walking distance using a distance-dependent algorithm, attempting to simulate changes in speed over longer distances.
- C16 - Interi.MAP: A Virtual Receptionist/Internal Navigation System for Offices
-

Christos Charalampidis, Jack Patrick, Panagiotis Georgoulias
Supervised by: Ian Utting
Project DescriptionThe primary goal of Interi.MAP is to provide an accurate navigation system for interior spaces along with a virtual receptionist service for offices/buildings. The main problem that we are addressing is the difficulty finding rooms or people in complex buildings and offices. Our design aim is to create an easy to use application, that doesn’t require effort to use and understand. The user provides their current location along with their destination and the system will overlay their journey on the map. Finally, the application is designed to be extensible for use in many different type of building and to be easy to maintain. For this project, we have used the University’s School of Computing as our building.
Results
The project is developed using Python and Django to create a website that is designed for smartphones but can also be used on desktop. The user can search by room, user or role to find where they want to go, and the current location of the user can be determined through QR codes placed on fixed checkpoints or by searching for a room they can see. The user’s location during navigation is estimated using step-counting to assist with following the path. An auxiliary Java program has been developed that can be used to measure digital maps, to automatically generate the Graph representation of the building from an SVG and to give Rooms descriptions, nicknames and room types. Finally, the system automatically scrapes the School Of Computing People page nightly, and uses this information to populate information about office locations, and to group staff together by common interests and research groups.
- C17 - UniPal
-

Danny Braund, George Matthews and Stephen Johnson
Supervised by: Ian Utting
Product description
UniPal is a mobile application that helps students track and manage their university studies and assignments. The aim of our project was to give students a cross-platform app that offered various different ways of managing their university studies and assignment process. With this, we designed a mobile app that would provide an intuitive design that allowed students to easily reach key tasks and deadlines as well as receive detailed information on their performance and time management throughout their course. Alongside this, we have built the UniPal app to be a dynamic solution to students differing requirements. By offering exam management alongside customisable module and task tracking features, we allow students to tailor Unipal to their own specific needs. Finally, Unipal would offer complete integration with the University of Kent SSO service to allow students to readily utilise the features of Unipal with their own existing Kent login.
Results
In our apps current state it allows students to manage and organise their module deadlines as well as exam revision and performance features. The design of the app is very similar to the Moodle page, catering to Kent students. We wanted the app to run on both iOS and Android platforms so we decided to use a cross-mobile platform Ionic, which uses a mixture of Angular and web-based technologies. The private Firebase database allows for synchronous storage that updates in real time, set and pull data to populate pages and supply us with mobile analytics. The app is split into four different sections:
1. Modules: goals and tasks can be created with timed reminders.
2. Exams: revision cards can be made with hideable answers.
3. Performance: tracks all of your progress updating alongside all other sections.
4. Notes: basic note card reminders for things that you need to do.
- C18 - Gathering Security and Privacy Expectations of Users from Mobile Apps
-
Laurence Barnes, Victor Diep, Amarpal Matharoo, Steph Abanis
Supervised by: Ozgur Kafali
Project description
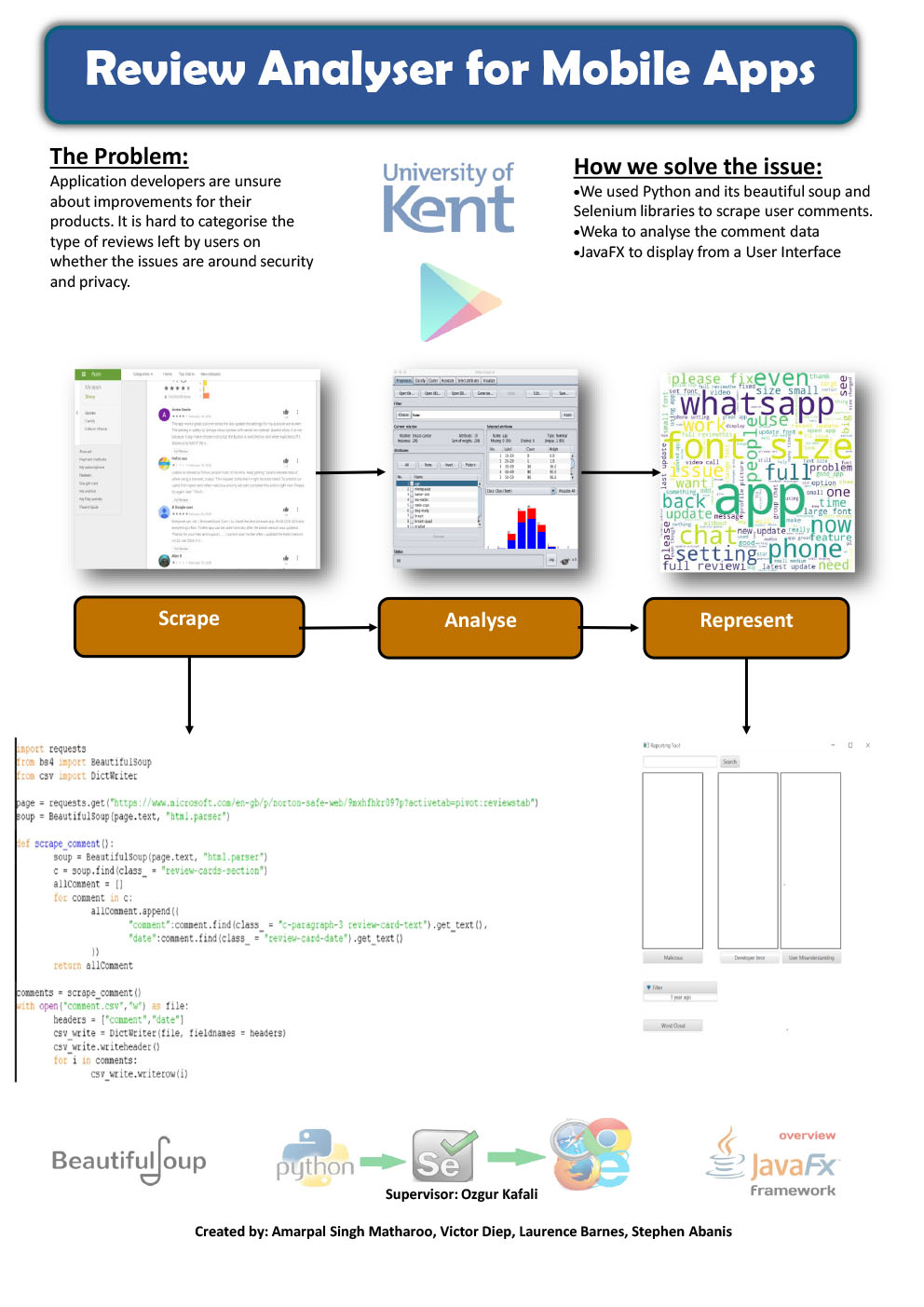
Using the Google Play application store, we are creating a Java application that can take reviews & create a word cloud from the data, as well as analytical data through the use of an open source application called WEKA With the use of the word clouds we should be able to analyse the frequency of the words in comments & use them to categorise the understanding of the users’ of the app.
The three categories are: Malicious, Developer Error, User Misunderstanding
We are also planning to use an application called WEKA to give us analytical data on the information that we have scraped. As it would be difficult to scrape the reviews in real time we are using a method of “web scraping” to collect user reviews & then store the reviews in a document to be processed & converted by our application into graph data. The data will be scraped from websites using Python.
Results
With internet application scraping which we used as a test, we saw between 45 and 246 lines of data scraped from the comment section of google play store applications. The time varied only slightly between web scraping tools but took a short time to collect from 5 seconds to 20 seconds. CSV has been our chosen type of file to store collected data in. With Python web scraping we are seeing results of roughly 10 comments per scrape in a relatively instantaneous time frame. Word Clouds are generated from our own java code but were initially generated from web tools as a test to give us some idea what they would look like using test data we had collected. It was without difficulty to copy and paste the data from comments directly from the google app store into an online tool to generate a word cloud. We have found it difficult to generate our own word clouds in java code and is still a work in progress with varying results. The UI will generate a word cloud from a document that we input and we will also word towards incorporating chart data after our application has processed the document into a word cloud.
- C19 - RentoHub
-
Obaid AlMansoori
Supervised by: Marek Grzes
Project description
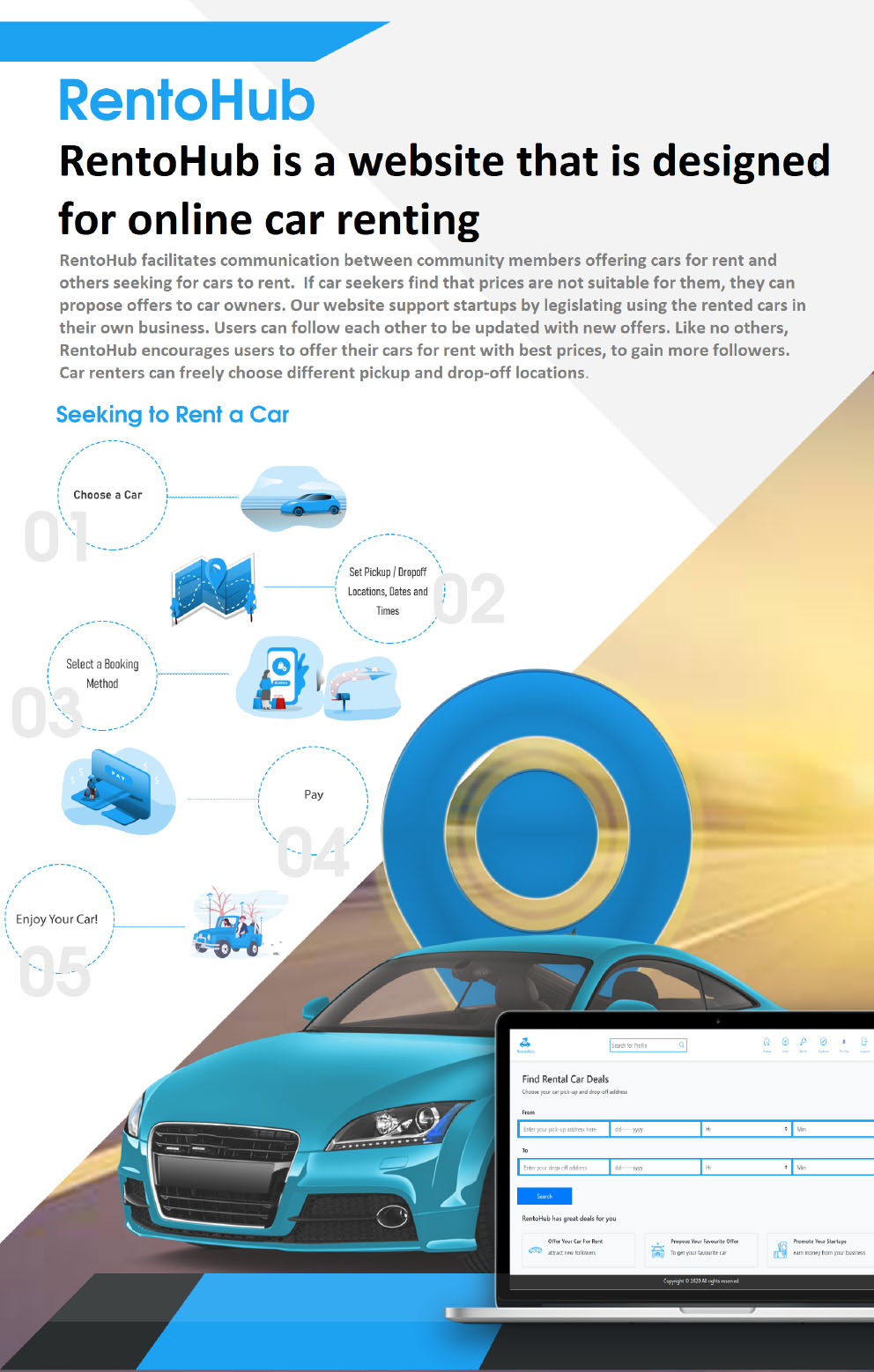
RentoHub is a website that is designed for online car renting. It is proposed to facilitate communication between community members offering cars for renting and others seeking for cars to rent. Unique features are introduced in the project, that's why RentoHub is distinguished from other similar websites. Firstly, if car seekers find that prices are not suitable for them, they can propose an offer to car owners, and then car owners may accept or reject these proposed offers; secondly, the website supports startups by legislating using the rented cars in their own business; and thirdly, the website's users can follow each other to be updated with new offers. The website encourages users to offer their cars for renting with best prices, to gain more followers. The also website allows car renters to freely choose different pickup and drop-off locations. A user-friendly interface is implemented to serve RenoHub community.
Results
RentoHub is developed on Laravel PHP framework. Laravel implements Model-View-Controller (MVC) architecture. Migration; a smart way for creating/controlling database, is paired with Laravel’s schema builder to build the website database. RentoHub is a secured website using Laravel Authentication System with password hashing, Laravel offers a high level of control over vulnerabilities such as Cross-Site Request Forgery, Cross-Site Scripting, and SQL Injection. In addition, RentoHub also offers session fixation prevention. For renting a car, the user determines the car’s pick-up and destination place, this feature is implemented using Google Place Autocomplete API, where the components of the selected addresses are automatically captured from Google Places database. Based on Nielsen heuristics, usability is achieved through a user-friendly interface design using Bootstrap v4.4.1 CSS framework. RentoHub creates a social network between users, through "following"/"view followers" features. RentoHub is available on an apache web server for the community.
- C20 - iris
-
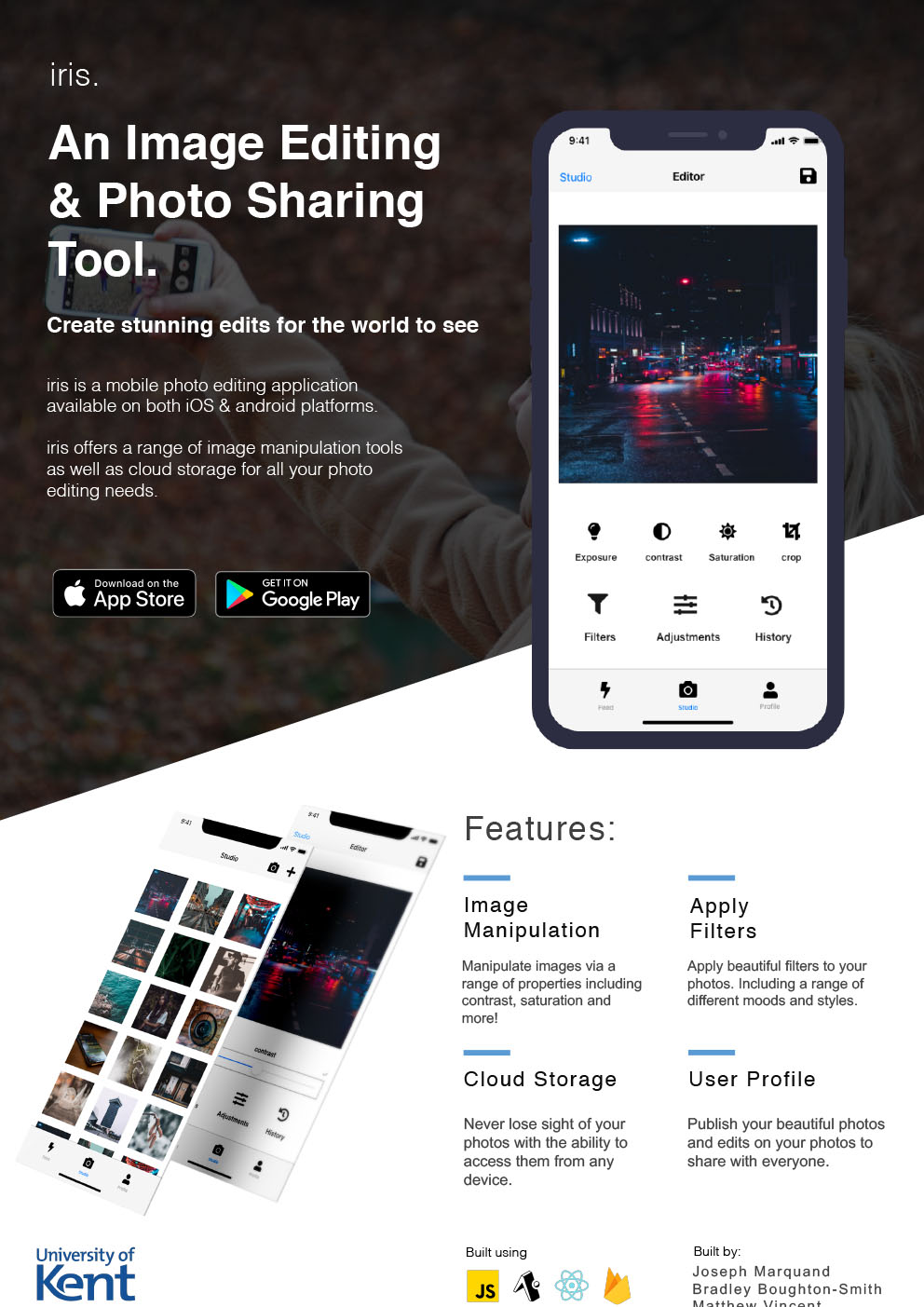
Bradley Boughton-Smith, Joseph Marquand, Matt Vincent
Supervised by: Peter Kenny
Project description‘iris’ is a photo editing and social sharing app. The photo editing side allows users to take photos within the application, and then have the option to edit them with features such as: crop, rotate, saturation, exposure, filters and more. Users are also able to undo or redo edits, and upload from their own camera roll. Once edited the user can post to their profile, save or discard the image. The social sharing side utilises Firebase to allow users to upload their photos for others to see, save, like, comment and so on. This also allows them to access their uploaded photos via any device that can run the app by logging into their account with their username and password.
The app has 3 main screens: Feed, Studio and Profile, providing a simple and self-intuitive interface for users to navigate the application.
Results
Our app is built using React Native, JavaScript, Expo and Firebase. To meet minimum requirements, our current prototype allows users to create an account, authenticate (via Firebase) and login. And then after allowing permissions can use their camera and storage to edit photos to their liking via a variety of photo manipulation tools we have implemented, and then publish them to the cloud.
The main focus is to have an app available from the Apple AppStore and the Google PlayStore for users.
- C21 - Bill Management Progressive Web App
-
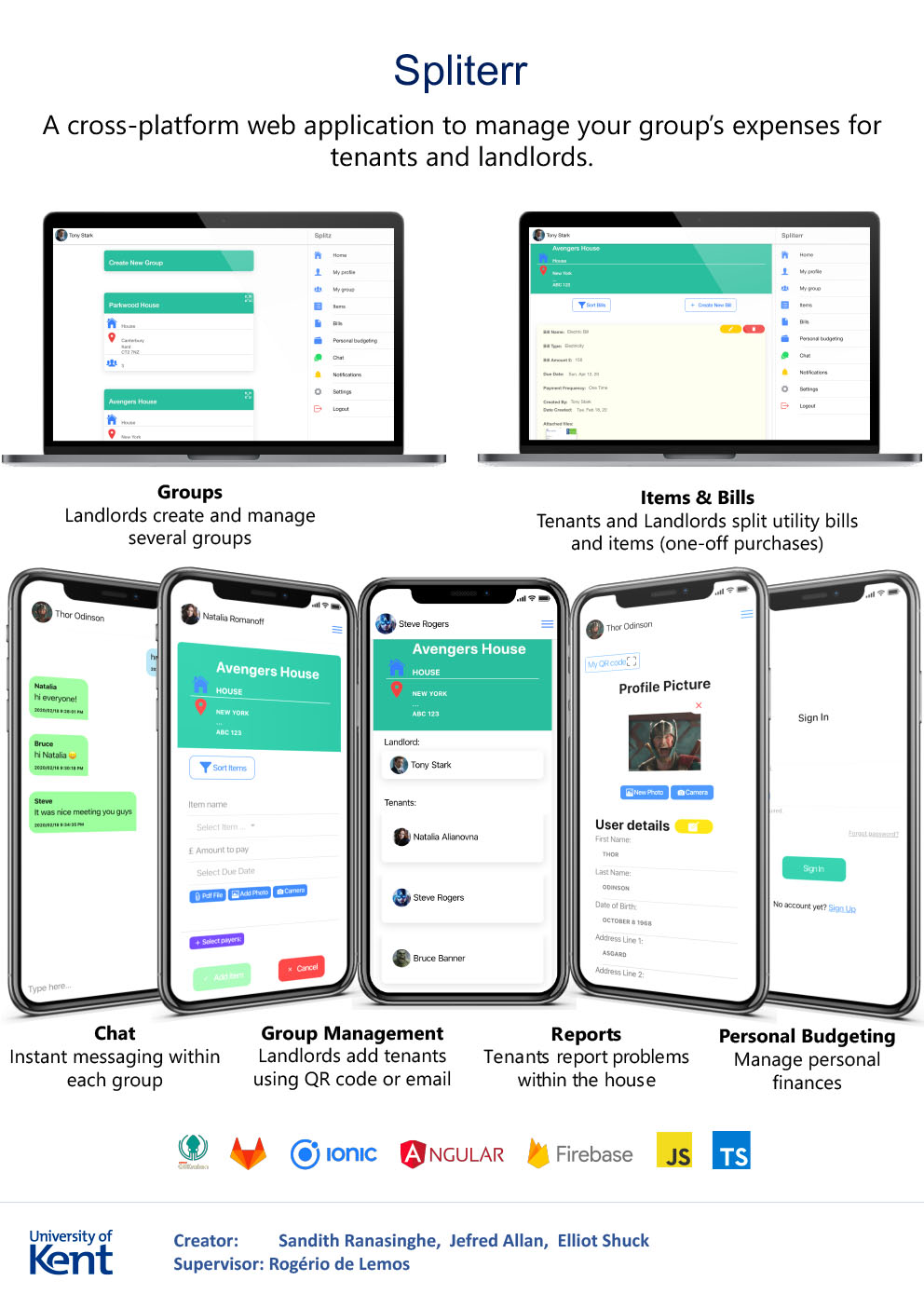
Sandith Ranasinghe, Elliot Shuck, Jefred Allan
Supervised by: Rogério de Lemos
Project descriptionOur aim in this project, is to provide a better management of services than an estate agent would offer through this web application for tenants and landlords.
The web application allows a landlord to create and manage their properties by group(s). The landlord can set up a recurring rent payment. The app allows tenants to split utility bills and items (one-off purchases). Tenants are also able to report problems within the house directly to the landlord. Tenants and landlords receive push notifications for items, bills, rent, chat messages and personal budgeting.
There are additional features that we have provided that an estate agent cannot. These include instant messaging between each group, for easier communication between the landlord and tenants.
A personal budgeting feature for tenants and landlords to manage their finances periodically set up by the individual. Tenants and landlords can also upload images and PDFs to the group(s).
Results
The web application that has been produced meets the aims that we set out in the project description.
We have created a progressive web application that allows you to run on any device that has a browser.
We have adopted the MVC (Model View Controller) software design pattern. For the model we are using Firebase. For the view we are using Ionic Framework and for the controller we are using Angular. The languages we used are JavaScript, TypeScript, HTML, CSS and Angular.
- C22 - Virtual Employee Analytics
-
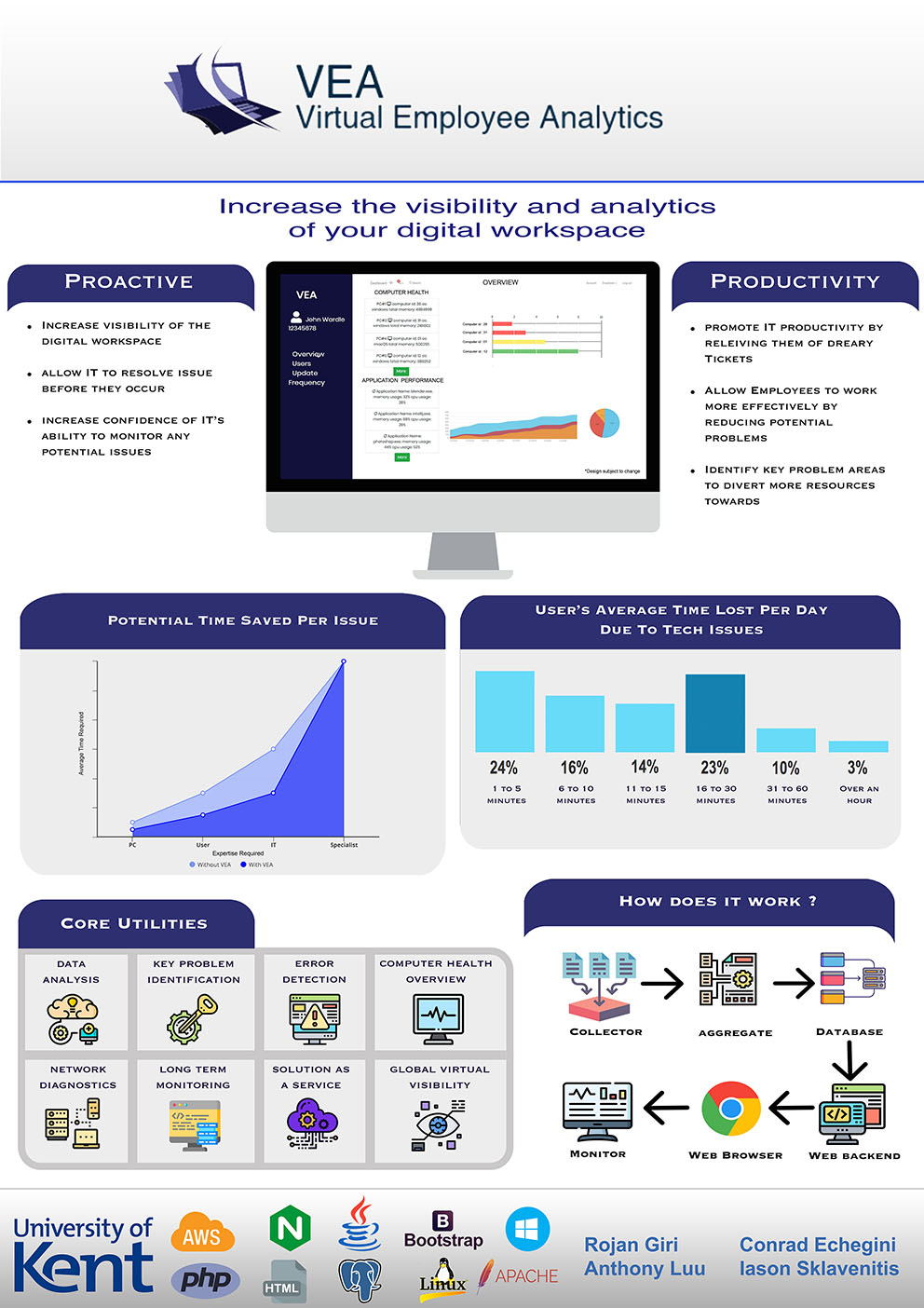
Iason Sklavenitis, Conrad Echegini, Anthony Luu, Rojan Giri
Supervised by Marek Grzes
Project DescriptionThe aim of this project is to create a product which increases the productivity of the employees and proactivity of the IT department in a company; the product increases the visibility and analytics of the digital workspace, by collecting, aggregating and analysing data. The company employees’ computers would have a collector software program which collects specialised data on a timer basis. All the data collected from each computer is sent to an Engine, a data aggregation and analysis server. The now complete data set would be stored in a postgres database, which acts as the main data storage for the front-end web application. The IT department would immediately be able to see all computer data analytics from the front end, and the product would highlight possible future issues as well as suggest fixes or recommendations to remediate existing problems.
Results
Although not complete, the product can already identify key problems from a given set of computers, and the user (IT) of the web-app can immediately act upon them. Whilst the product does not provide automatic solutions for certain problems (such as defragging, cleaning up hard drive etc.), the user can manually solve the current issues. The user can identify programs which have a big CPU and memory consumption, and in turn identify if any computers that are struggling because of it. Thus, any required upgrades for employees can be acted upon; any other problems such as high memory consumption of computers without any specific programs, or slow computers are also highlighted by a normalized value indicating “Computer Health.” Computers with a low computer health value are highlighted up in the overview page.
- C23 - Project F.R.A.M.E (Facial Recognition Attendance Monitoring Engine)
-
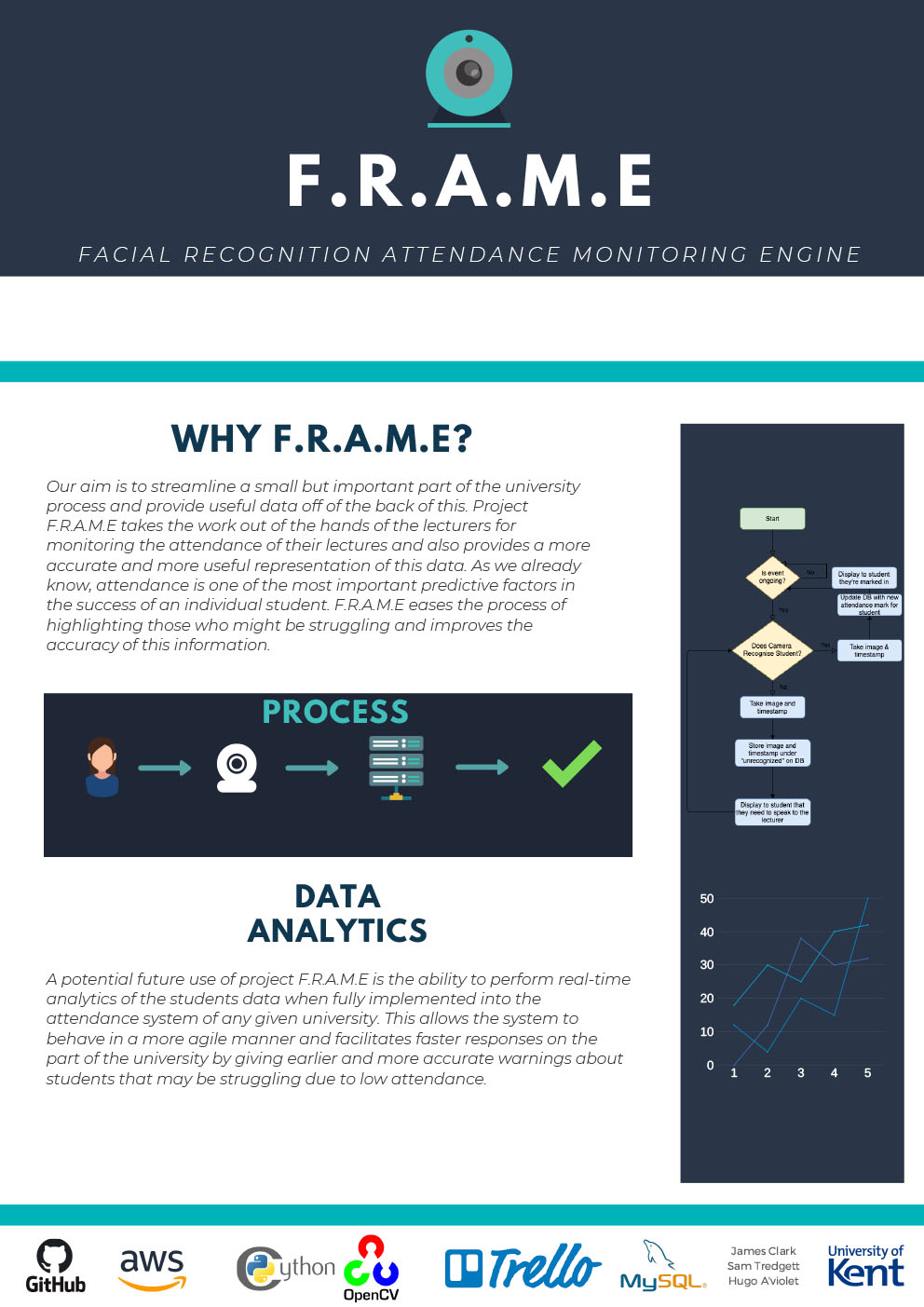
Samuel Tredgett, James Clark, Hugo A’Violet
Supervised by: Marek Grzes
Project descriptionAttendance is one of the key factors that predicts success of an individual student on any given course. However, it can often be difficult to keep an accurate track of students in attendance without taking time from the lecturers day to hand out paper, wait for all students to sign next to their name, assuming they’re honest about it, and register that into the university attendance system. This process is wasteful both in time and paper, as well as having large room for inaccuracies.
The goal of Project F.R.A.M.E. is to take this workload off of the lecturers’ hands and fully automate the process. This will be achieved through the use of facial recognition techniques and back-end systems development in both Python and MySQL. These systems will interface with one another to provide lecturers with detailed and accurate reports of who attended which event and when they attended it.
Results
As a team, we made sure each of us was at the same level technically in terms of ability to program in both Python 3.5 and MySQL. This was achieved through use of online resources such as Educative, Lecture recordings from our prior year doing software development, and other packages from the GitHub student bundle. We also organised ourselves using the online tool Trello for keeping an accurate track of our current project pipeline and used GitHub as our primary form of file transfer and storage.
At this point in time, we have implemented a very basic prototype level of functionality including the cameras ability to track faces on show with good accuracy and have made some further progress in interfacing between a local python program and a back-end AWS (Amazon Web Services) cloud storage. We’ve also managed to outline some areas of potential future developments which could be added on to the existing project.
- C24 - University Capitalist
-

Sina Sanaizadeh, Andreas Konstantinidis, Babajide Gomez, Rushi Patel, Samuel Omede
Supervised by: Radu Grigore
Project descriptionUniversity Capitalist is an Android Mobile game which features elements of Incremental Games and Idle Games where you aren’t necessary required to continuously play the game to make progression but doing so will speed up game completion. The game will allow users to build and develop their own University in their own way by selecting which departments they would like to create and purchasing additional rooms in the buildings to further develop them and make more money from them per rotation. The game is developed on Unity and in C# due to its versatility as an app development platform and a coding language respectively. The game is bolstered by side objectives and events that occur in the game such as random Quiz questions to earn more money (or lose it if you get it wrong) as well as a rare Alien attack which was foreshadowed by cryptic messages sent earlier in the game.
Results
The game we have created meets the goal we set from the beginning; most of the goals listen in the description have been met. When launching the game, the user must enter the name and select a school from school of economics, school of computing, school of biosciences and law school to start with, then the player already owns a lecture room and a seminar room but can unlock more after meeting certain condition such as accumulating enough funds. A player can proceed to unlock more school buildings and fully upgrade them to max. A player can unlock the monument building which attracts aliens to attack the university and can also unlock defence system which can be used to defend against the aliens. The game has a set 50/50 chance of spawning aliens or posting quiz questions from all the schools. The various schools can be rebuilt if destroyed by aliens by spending some money to complete the repair. The game is finished when a player unlocks all schools and fully upgrade them. We had another goal which was to make the game dynamically resizable but unfortunately, we were unable to achieve it. Regardless, we completed all the major goals of the game.
- C25 - TeeVee – The One Stop Shop for All Your TV Needs
-

Shakil Choudhury, George Johns, Jordan Norris
Supervised by: Dominique Chu
Project descriptionThe aim of this project was to provide a centralised place to manage all your TV shows in the form of a web application using modern web technologies. In the age of streaming, it is harder to keep track of the shows you watch across all the various platforms available. The application should allow users to add shows to their watchlists, check off episodes as they watch them, see upcoming episodes, follow their friends, see their friends’ ranked watchlists, and get suggestions.
Results
We designed and developed a decoupled web application made up of a Node.js Express based API using REST techniques, persisting data in a PostgreSQL database. To complement this server, we produced a modular React front end with a state managed by Redux and styled responsively with Sass. We sourced TV show data from the TVMaze API, which we keep up to date with a housekeeping microservice.
Our application allows users to:
Create accounts or sign in via Google (OAuth2); Add shows to their watchlist; Easily check off episodes on the backlog as they watch them; See on the calendar if new episodes from shows they watch are airing this week; Rate shows on their watchlist; Review shows; Follow their friends; Get suggestions based on people they follow.
- C26 - Zombie Apocalypse
-

Joe Godwin, Olabode Bello, Kasim Hussain, Jakub Wysoczanski
Supervised By: Peter Kenny
Project descriptionThe Zombie Apocalypse project aims to create a moderately realistic simulation of zombies and their behaviours. Players will be given the capabilities to defend against these zombies in a tower defence inspired gameplay loop that will see them fighting off waves of zombies who are attempting to raid their central settlement and eat all of the last remaining humans. To aid in this defence players are able to position a variety of walls and turrets around their settlement and can assign each of these objects with specific behaviours and priorities to help ensure that their town does not get destroyed.
Results
Our project was developed in Unity. We have managed to produce a reasonably in-depth simulation of zombies that follow core flocking behaviours as well as developing a few specific behaviours that promote the zombies attacking objects that threaten them as well as attracting them to our central city. To defend against these zombies we have built several different variations of turrets such as machine gun turrets, missile turrets, flamethrower turrets and even a laser turret. We have also designed placeable walls that will help players slow down zombies that are approaching from a particular direction. Both the turrets and the walls can be added at runtime using our custom grid-based building manager which allows us to constrain players whilst still offering quite a lot of freedom in terms of object placement.
- C27 - Arduboy Game Studio
-

Thomas Homsy, Donatas Paplauskas, Dallas Frankel
Supervised by: Daniel Knox
Project descriptionHome-Made Arduboys are a fun way for kids to make their own custom games on a Gameboy like device. We found out that to make games for this, children will need learn to code in C/C++. Our project was to lower the barrier and create an easy-to-use game creation tool that features a Scratch like block-based language. We know of an open-source library by Google called Blockly. This library supplied us with the visual drag-and-drop blocks interface. We need to generate C/C++ code from these blocks that can be uploaded with the press of a button to the Arduboy. We like the idea of a sprite creator which allows users to easily create custom pixel art that can be added into their game. The system would have functionality for saving, loading, compiling and uploading projects.
Results
The software developed uses the Vue library along with Bootstrap CSS framework. This helps when making the user interface as it allows for interactivity on the page. There are several custom blocks we added for the Blocky Framework that adds Arduboy specific functionality. It has a Sprite Editor that can be used with our multi-tab ability, to make many instances of different Sprites that anyone can create. We developed Block-to-C functionality which is essential because that is what is used to program the Arduboy. After the previous function has taken place, you are able to compile and upload your programs straight to the Arduboy.
- C28 - Food Rescue
-

Charmaine Kambabazi, Rajsewak Babra, Nandi Moyo
Supervised by: Sally Fincher
Project DescriptionFOOD RESCUE helps bring together the zero food waste community. The platform enables our users to reduce the growing problem of food waste with three ways to participate. Our users can:
- donate unwanted food items, and save food items donated by others;
- rescue meals from local restaurants at a reduced price;
- Bring to the Table. This is where users can bring unwanted food items, learn to cook with them, and eat a meal together as a community.
- C29 - PedCross
-

Mohammed Asran, Sam Oweka
Supervised by: Dan Knox
Project descriptionFor our project we were tasked with the development of a website. The purpose of this website was to provide data to the public about the number of people using a crossing located in Canterbury. This data would be provided from a device created called PedCross.
Our website aims to help users gain a full understanding of why the PedCross was created and how it can be used to benefit society. The website was built using Lavarel framework and GitLab was used for version control.
Results
At this moment in time users are able to view data on our data page, get a better understanding of what we are doing using our WhyPedcross page, view where the device was used on our map page, and make enquiries thanks to our contact page. Our website also has a function allowing users to generate a pdf format of data which can be used by local councils across the UK. In addition, we have included a function that allows users to sign up to our newsletter, in order to stay updated with any new developments we make in the future regarding the PedCross device. We hope to improve a few existing functionalities over the coming weeks and also add an authentication process.
- C30 - Uni-Review App
-
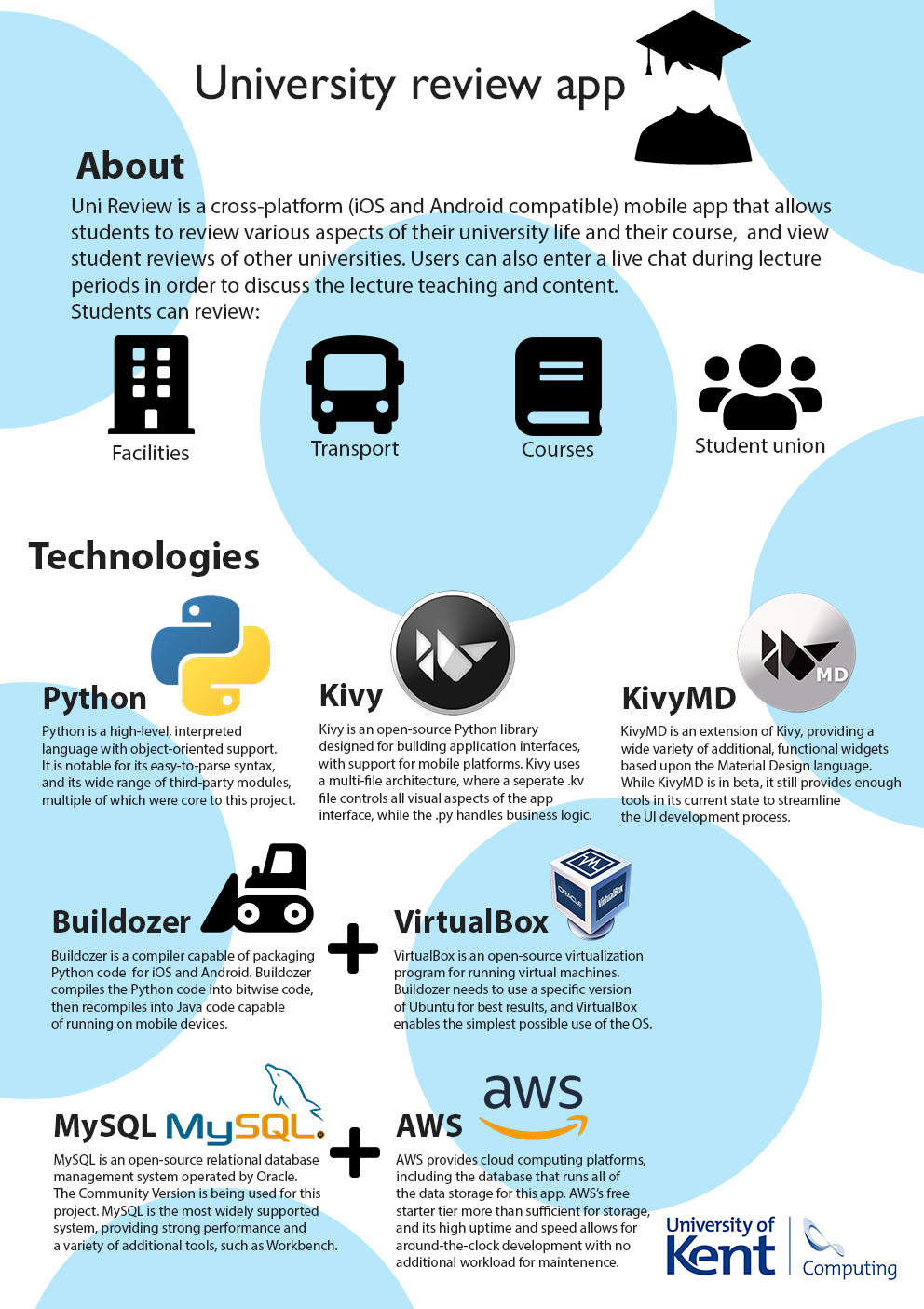
Charles Thomson, Howard Burroughs, Kalvin Kataria, Finlay Monblat
Supervised by: Tomas Petricek
Project descriptionWe aim to create an application that acts as a platform to allow current students and alumni to give detailed hands on reviews of a university based on factors that are not covered in a university’s promotions. Additional tools will be given to the user, such as live chat rooms for discussions with current students, on matters such as courses and facilities, to a comment-based system on each review. The app aims to provide a new student with as much real-world information as possible so they can make a truly informed decision about where to go to start their path into higher education. The application will be cross platform (Android and IOS) and will be written in a non-native language to application development.
Results
We have produced the application in Python and have then used Buildozer to make the conversions necessary to allow the application to run on Android and IOS. Kivy, and a subset of Kivy (KivyMD), have been used to create a working UI that allows a user to navigate through several pages relating to each university available on the application. Data is stored using an external cloud-based database that can store information relating to each university along with login in credentials for each user. Reviews can then be published for each page, with each review providing a score that is then averaged to show a final score for each page, and revies can be upvoted and downvoted, with the most popular reviews being shown first. Finally, users can join a synchronous live chat in order to discuss content in further detail.
- C32 - React Integration Plugin for Django
-

Filip Grebowski
Supervised by: Ian Utting
Project descriptionWith a growing need to support modern frontend frameworks in older, less extensive, and less flexible projects, this particular case integrating React into Django -- a monolithic framework -- is made more difficult by the differences in logic, syntax and execution model of the two frameworks.
This project will produce an integration plugin designed to support a seamless workflow of adding React applications under specific URL’s of the Django project, offering an easy-to-use CLI for setting up the configurations and doing all the heavy lifting for the developer. The Integration plugin will create a new folder structure for manipulating a basic React boilerplate application, performing setup, and adding to an existing configuration, along with a fully dockerized build process. The whole idea is to not only reduce the complexity of such an integration, but to also reduce the difficulty and to speed up the entire integration process.
Results
The project is offered as a package that the user can download and use within their Django project. Upon running a simple command in the CLI, the user will be prompted to consider how many individual React applications they want to create, and at what URL paths those applications should be created at.
After the user decides on those criteria, the plugin will navigate the whole current project structure, find the relevant “settings” and “views” file, insert all the base configurations, generate the index files with the root names, assign ports to each React frontend, and build everything through the use of a Docker file.
At this stage, the user will be able to navigate to the URL that the Django application is running on, direct to the specific URL of one or many React applications that they have created and see the boilerplate project ready to be used.
- C33 - A Lifestyle Application Written in a Functional Programming Language
-

Daniel Fisher
Supervised by: Tomas Petricek
Project descriptionDue to the recent boom of fast food delivery companies and easily accessible sources of junk food, obesity rates have soured. Compounding this there is great concern that a diet heavily composed of fast food will not supply the nutrients needed for full development in children and adolescents. Nutritional information for these foods are often available online, however it is often challenging to access.
I propose a comprehensive lifestyle management application that collates nutritional data from various fast food, supermarket and convenience stores, presenting it to the user in a concise analytical manner. The goal of my project is to allow people know exactly what they’re consuming, using a range of graphs and widgets to track past eating patterns and predict future suggestions for meals to afford the user a nutritionally balanced diet. My hope is that my users can use the application to monitor and improve their lifestyle habits.
Results
My application collates data from various online sources and presents it to the user to help inform their dietary decisions. CSVs are used to store the nutritional data and plans for python-based web scraping are in motion to collect live data from the relevant web sources. Graphs and images are used to represent data to the user in a clear concise format to avoid confusion and simplify results. Meal suggestions are recommended based off of past dietary data to encourage users to have variety and substance in their diet.
Nutrition will be available on the google play store and hopefully the Apple App Store in the future so that it can reach a wide audience. Users will be able to share images with one another through the image sharing feature to build an active community so that the app will see real world use.
- C34 - Menyou
-
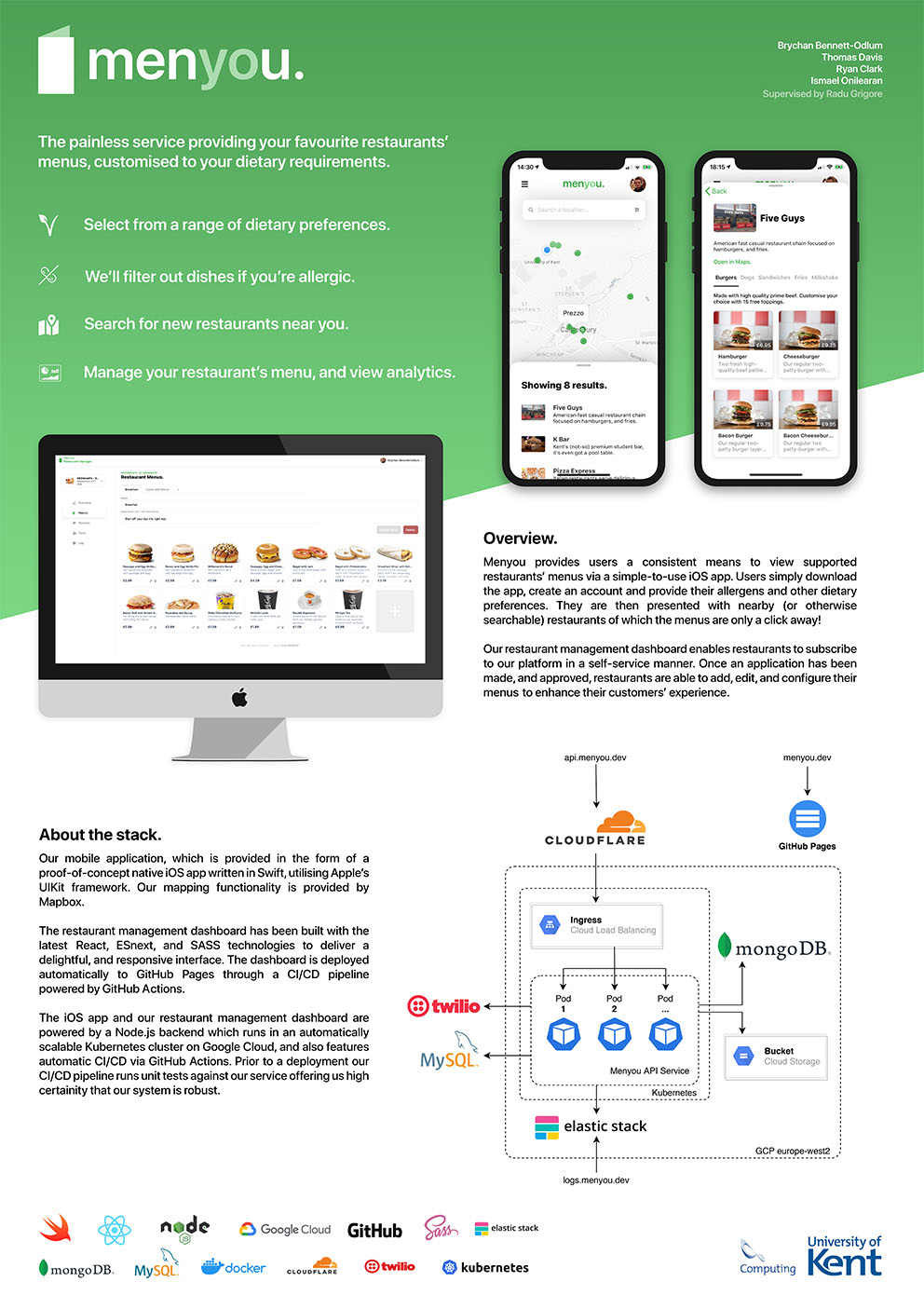
Brychan Bennett-Odlum, Thomas Davis, Ryan Clark, Ismael Onilearan
Supervised by: Radu Grigore
Project descriptionMenyou is an app designed to suggest and filter restaurant menus based on the allergens and dietary requirements of users. In modern society, it can be difficult to accurately match up your own diet to suitable options at the restaurants you want to eat at — a problem we attempt to solve. We invite restaurant managers to sign up to our web-based dashboard platform, where they can monitor and edit restaurant information, staff roles, menus and dishes, so that the latest information is always at the fingertips of the user. Data communication between the web application and native mobile application will be managed by an API layer, providing an interface to a secure clustered database.
Results
Users are able to select which allergens affect them and which diet types they subscribe to when signing up to the platform. Our iOS app then uses the geographic location of restaurants to identify and filter suitable menus nearby, allowing users to view individual dishes with all the information they need to make a decision. Following a quick approval stage, the restaurants themselves can be managed by staff members using our React-based dashboard. We feel the products we have built promote food safety and diversity for the user and ensure they are able to confidently visit nearby restaurants, knowing there are food options that are suitable for them.
- C35 - AnyVinyl
-

Darren Booker
Supervised by: Daniel Knox
Project descriptionPhonographic recording is the oldest audio sampling and reproduction method.
Affordable 3d-printing has come a long way. But, is it yet able to record an audio signal in the way that vinyl records do?
The software will transform a digitised audio input (e.g. using midi, wav, or mp3 file) into a phonographic model ('vinyl' stl file). Current 3d-printing technology will print the model. The printed model can then reproduce sound like any other vinyl record.
The ideal outcome would be to reproduce a good quality (record-like) sound.
Many aspects will need research. Including, recording sound onto a disc, standard record specifications, wav file format, stl file format, and producing a 3d mesh.
Results
The software uses iterative intervals of audio input to create polygons which represent the groove for that moment in time. These polygons are then cut from the disc model to form the record model. Scaling for the grooves allows trial-and-error to find the best stylus reproduction.
The resource requirements were too immense to make use of existing software. So, the AnyVinyl program accomplishes every part of the design. Several technical and mathematical challenges were overcome and combined to produce the record.
The record has a silent lead-in and lead-out track surrounding the audio. The audio can be partitioned into different tracks with a silent crossover track between each.
The record groove has very small variations. So, the 3d printer must use the highest resolution possible with the smallest available nozzle (0.2mm).
- C36 - Castle Clash: An Immersive Multiplayer Game Experience in VR
-

Denis Domide, Adriana Samareanu
Supervised by: Dr.Özgür Kafalı
Project descriptionCastle Clash is a multiplayer game played in virtual reality designed for a quick and hands-on immersive experience. Both players will be connected through local network and can play through VR headsets such as Oculus Quest. Once entering the game environment, each player is presented with their own castle and cannon built upon each side of a long table. The objective remains for each player to use their weapons (such as various objects that can be loaded into the cannon) to destroy their opponents castle before their own gets demolished. Players can cast protective spells in order to diminish the damage and hence also reduce the amount of health points lost usually. Once one castle has been completely destroyed, that player has lost the game and the one with the last castle standing has won. The game is designed in C++ and constructed in Unreal Engine 4, a game engine specifically suited for the storage capacity and graphics compatibility with VR.
Results
Working with UE4 has allowed for the game to be produced with quality graphics and realistic game-play scenarios. Algorithms were specifically designed to cater to a range of players, considering multiple aspects to make the hands-on experience as realistic as possible. For instance: player motions are as natural as possible, and are not restricted to ‘left-handed’ or ‘right-handed’ people by allowing both remotes to work interchangeably. Another example includes the mechanics of aiming and firing the cannon, where the given algorithms allow for easy ‘aim and shoot’.
Ultimately, the game has reached levels that allow for general use and can also be expanded for in the future should development continue. Given the right resources, new implementations can include a machine-learning opponent using neural networks and online game connection to play with opponents around the world.
- C37 - CabLink
-
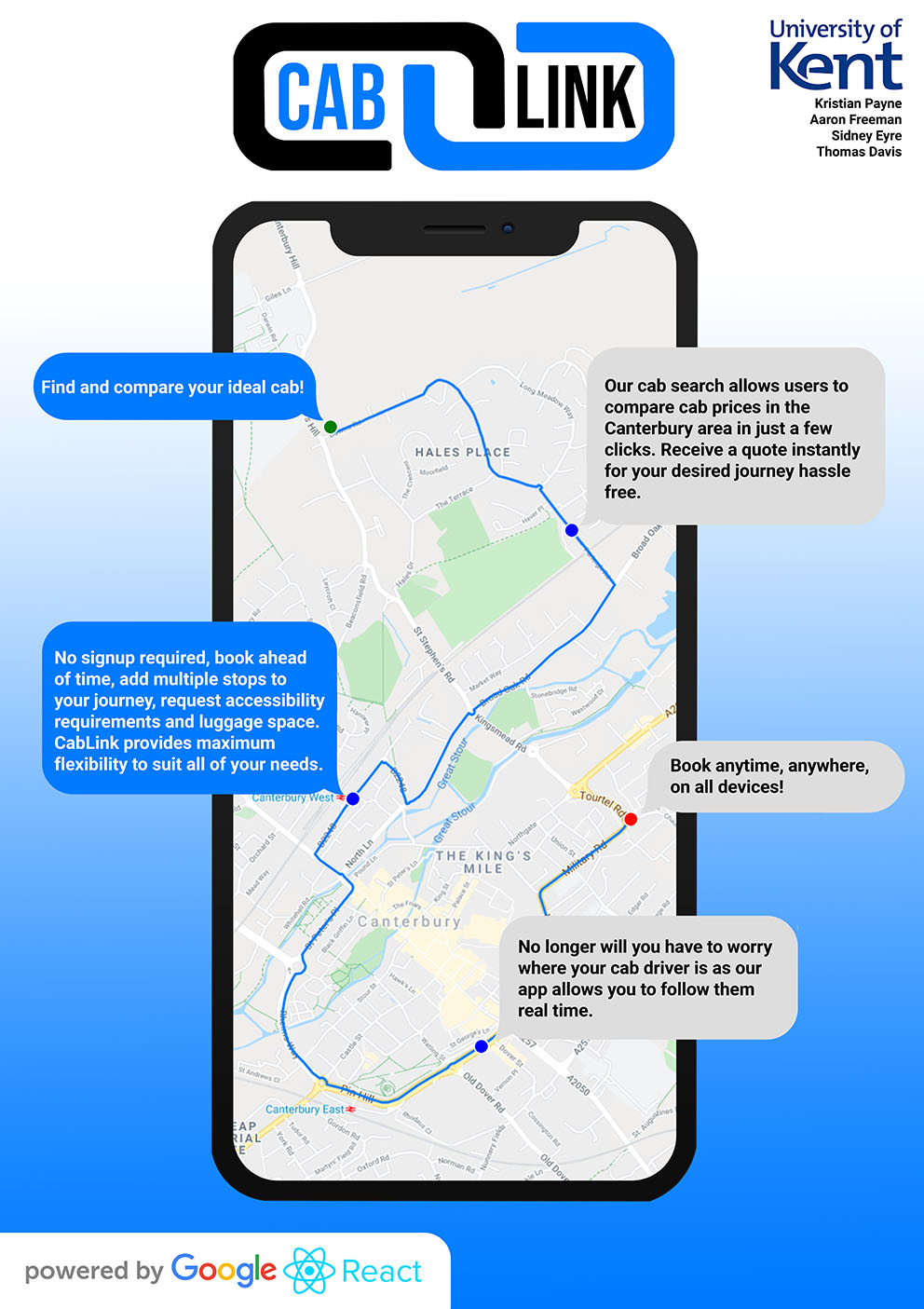
Kristian Payne, Aaron Freeman, Sidney Eyre, Thomas Davis
Supervised by: Richard Jones
Project descriptionThe aim of this project is to make an app that is accessible across multiple platforms. It should enable users to book a Taxi from a set of recommendations provided to them by the app. These would be the quickest and cheapest taxis available at the current time or at a time designated by the user. Customers are given the opportunity to sign up for an account allowing them to track their bookings and save payment details, although not required. Multiple stops added to each journey take into account the best available route. The React framework when creating the application should interact with the
Google Cloud Platform to provide up-to-date services to the users. We utilise our own external database to create, store and manage accounts.
Results
The current version of the project clearly meets the initial criteria we set out in the early stages of the project, users can create an account, store payment details, obtain available taxis on their route of choice with the quickest and the cheapest options displayed. In addition to this there is the functionality to book at later times, add additional stops and delete accounts/payment details if required. The UI has been implemented to be simplistic and easy to use, with the mapping and start and stop points being easily identifiable. Our database stores passwords, usernames and personal information to then be used within the booking page and account pages to track bookings and payment details. The site was built using Node.js and the React framework.
- C38 - Ethics Generator – Autonomous Ethics
-

James Scarry, Kieran D’Arcy, Taylor McNicol, Ibraheem Jhanji
Supervised by: Özgur Kafali
Project descriptionAutonomous Ethics is a generator designed for the purpose of testing various moral and ethical dilemmas, more particularly in the area of autonomous vehicles. Our project, Autonomous Ethics, presents the user with a number of scenarios focused around exactly that. The premise is as follows: An autonomous car (may contain passengers) is approaching an unavoidable accident; for the sake of the test, it is assumed that the brakes have failed and is approaching a pedestrian crossing (with zebra crossing, red light and green light being the variables). Two of the three options will result in the death/injury of the pedestrians present. The third option will always involve your own death/injury.
It is in the hands of the users to make the assumed choice of the autonomous vehicle. The generator was built to question the current dilemmas that experts in the industry are facing with autonomous morals. Autonomous Ethics is designed to look further into the differences in moral and ethical decision-making, as well as detecting potential biases in a user’s decisions. The generator will alternate between putting the user on a time-limit and allowing an unlimited amount of time; the aim of this is to see the differences in choices (if any) when a user is given different circumstances.
The finished generator will adapt the scenarios the user is presented with, based on their prior decisions; this allows the generator to play more into someone’s specific moral standing.
Results
Our project has 28 graphical characters that are randomly generated to bring a degree of unpredictability and genuine unique scenarios for each user. For these characters a class, ability, age and gender system are used to be able to draw data from these specific identities. Implementation of three crossing types with timers arbitrarily introduced on numerous scenarios adds a deal of complexity and pressure the user will experience. Further development will include logical scenarios based on the user’s previous responses which would be selected and moulded from a bank of 3.6 trillion possibilities. The results page provides statistical analysis of the options the user choose from the scenarios, where they can bear comparison with other users. Also giving some details on where in the spectrum they may lie in, in terms of consequentialism and deontology theory. This is all presented on a server and webpage we have constructed which runs seamlessly in correlation to the ethics generator.
- C39 - GOLF: A Programming Language with a Twist
-
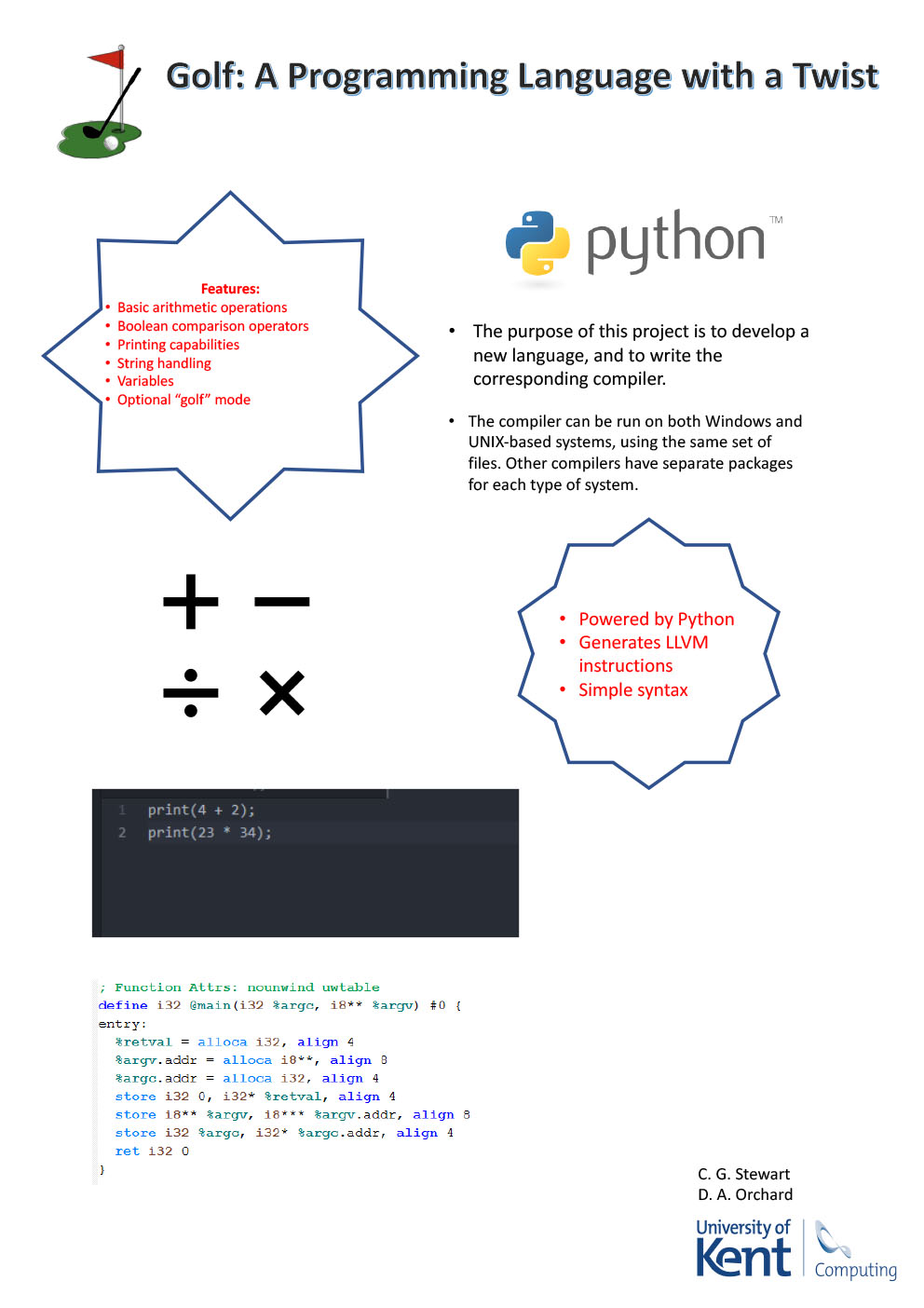
Callum Stewart
Supervised by: D. A. Orchard
Project descriptionFor this project, I developed of my own programming language, and wrote a compiler for the language. The compiler was implemented using the Python programming language, and targets the LLVM instruction set. I chose to target this instruction set, rather than compiling to assembly language, because the code that was generated was much shorter and compact than it would have been in assembly language. This decision was also due to the fact that the syntax of the generated code was a lot simpler, and therefore it was easier to write scripts that I could use to test the outcome of my compilation without implementing it in the compiler beforehand.
This project was a modification of the original project that was proposed, which compiled a language called Granule and compiled to the Erlang Virtual Machine. I decided to modify the original project because I wanted to develop a compiler in a language that was more familiar to me.
Results
The end result of the project was a basic programming language, which consisted of a lexical analyser (lexer) and parser, code generation, and an abstract syntax tree (AST). The lexing and parsing phases of compilation are handled using the RPLY library, which is a version of the Lex/Yacc toolset that targets a subset of Python called RPython. The language is built to be able to handle simple arithmetic expressions, printing to the terminal, Boolean comparison, variables, and strings.
The language is not Turing-complete, as I do not have the capabilities to perform loops in the language, but it has most of the basics that are found in simple languages. It is a weakly-typed language, like JavaScript, as it has the capacity for types, but it is not necessary to state the type of a variable when it is being declared.
- C40 - Vortex, Simulated Cryptocurrency Trading Platform
-
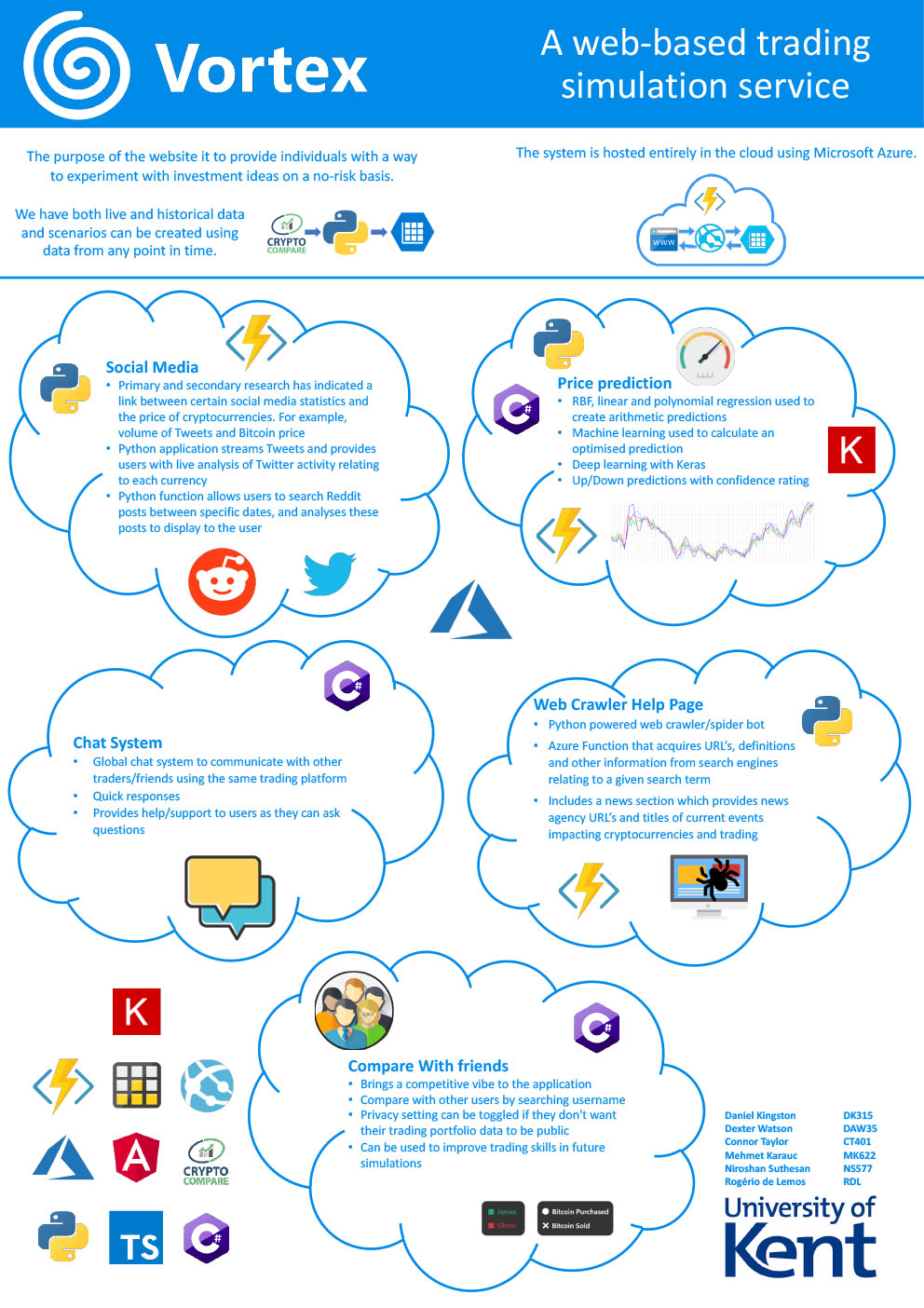
Daniel Kingston, Dexter Watson, Connor Taylor, Mehmet Karauc, Niroshan Suthesan
Supervised by: Dr Rogério de Lemos
Project descriptionWe acknowledge the significant financial risks associated with cryptocurrency investment. Vortex is a web based, simulated cryptocurrency investment platform which addresses this issue by allowing users to practice and gain knowledge of its concepts without financial loss. Users will be able to log in to our website and simulate buying and selling cryptocurrencies. Users will be provided with various sources of information to assist in making investment decisions, including their own history of transactions, price prediction methods, live chat between users and social media data.
Results
We have developed a website called Vortex which allows users to select a starting balance and use this balance to create and manage a cryptocurrency portfolio. The website uses the Angular 9 framework, connected to a C# API hosted in Microsoft Azure. The project is hosted exclusively in Microsoft Azure as it provides an easily manageable, cost effective solution and has reliable data handling. We downloaded currency price data from a free API called ‘CryptoCompare’ and stored this in Azure Table Storage to allow for quick access without relying on a third-party API. Further features such as social media integration, web help and price prediction are elements that have been implemented using Azure Functions written in Python.
Users can compare their performance with friends, as well as view various price prediction metrics, which will display numerous charts informing users about the potential changes. Relevant information from various social media websites is also available to allow users to make more informed decisions.
- C41 - rizumu - An Online Keyboard Rhythm Game
-

Ben Orchard, Ashwini Bhandari, Joshua Hunt, Ozioma Ezechukwu
Supervised by: Tomas Petricek
Project descriptionrizumu is a key-based rhythm game. Similar to Guitar Hero/Dance Dance Revolution, notes scroll down the screen and the player must time their keypresses with the backing music. The more accurate you hit notes, the more points you score. Players’ scores are stored online and publically viewable online. Players should be create and edit their own tracks. If possible, tracks from similar games (Stepmania, beatmania, osu!) should be importable.
There are two distinct artefacts to this project: the game, and the associated website.
Project extensions are focused around gameplay effects and website features, like displaying local rankings (e.g. country), and adding some visual effect spice.
Results
We decided on using Java for the cross-platform support and to match our group’s existing knowledge – similarly, we picked CodeIgniter for the website. In the game client, players select tracks to play and have to hit notes as they scroll. Finished plays have their scores uploaded to a shared database, which the game’s website displays in various listings. The website has user authentication, also shared with the game, so scores are tied to a specific user.
One achievement we had was Josh implementing conversion between osu!mania tracks (a free rhythm game with similar mechanics) and our internal format. This gives us a huge corpus of existing tracks for users to play.
- C42 - Schroders Shortlinks
-
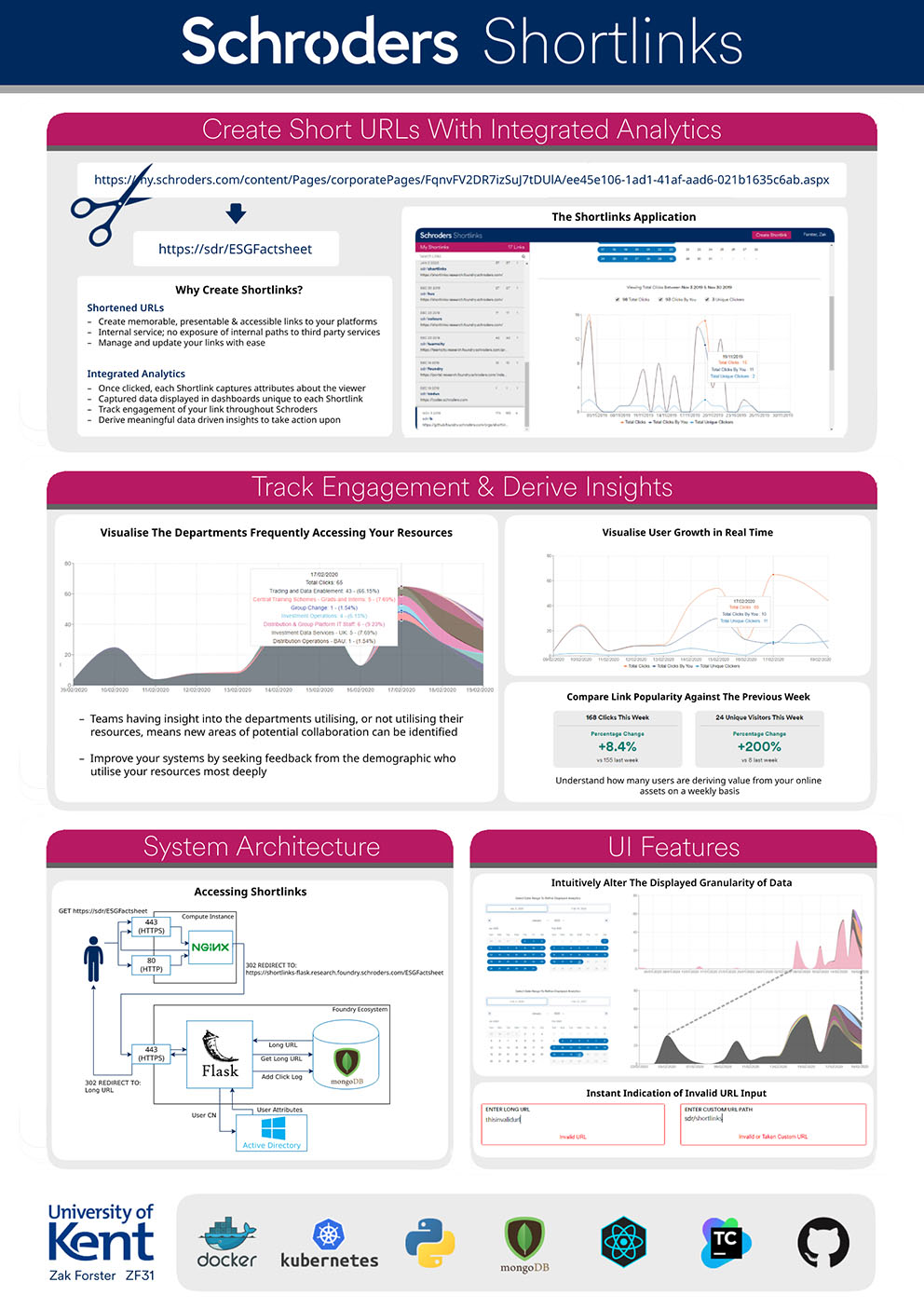
Zak Forster
Supervised By: Stefan Marr
Project descriptionShortlinks is an analytics platform accessible within the Schroders intranet. With Shortlinks, employees can create custom memorable URLs to their web-based resources, with integrated analytics.
Once clicked, each Shortlink stores attributes about the viewer and their compute environment. The data is visualised through dashboards unique to each link. Shortlinks extracts viewer attributes from our employee directory (Active Directory); affording link creators a deeper insight into their userbase, than is offered by third-party services, for instance, the departments within Schroders accessing your link.
Shortlinks originated as an Innovation Challenge concept, initially to make lengthy auto-generated intranet URLs memorable. Secondly, it sought to provide insights into the audience and departments deriving value from our online assets, enabling the best possible data driven decisions to be made.
Results
A Shortlinks minimum viable product that provides users with the aforementioned features was successfully delivered. Initial results are encouraging; after 5 days Shortlinks has attracted 43 unique users from 23 departments. A total of 54 links have been created, through which 321 clicks have occurred.
The Distribution Operations team in particular are utilising the platform, having replaced all URLs on their intranet homepage with Shortlinks, enabling analysts within the team to track usage for internal business reporting purposes.
Future work is expected. Feature requests from users include shared link ownership and adding support for data exports. Data exports will enable custom dashboards to be created for precise team needs.
- C43 - Let's Play! Building Games to Increase Security Privacy Awareness
-

Alex Baker, Conor Moore
Supervised by: Dr Jason Nurse
Project descriptionWe are researching the effectiveness of using gamification to raise the knowledge and awareness of cyber security and privacy topics. To achieve this, we have made a game where the player is a wizard and must travel around maps and solve puzzles, avoiding several threats throughout, whilst opening chests by completing questions on the related topic. Where incorrect answers are given, feedback is provided to the player and a new question is asked. Players will then get an opportunity later in the level to repeat the question. Each level relates to a new topic containing fresh unseen questions.
Results
We have created a fun game for teenagers to increase their cyber security and privacy awareness by questioning players within our game on related topics and providing feedback to assist with educating players throughout. Our game contains questions relating to communication security, data security, social media privacy and smart devices privacy and players are given feedback for incorrect answers so they can gain knowledge on the related topic.
Human participants will be required to complete a questionnaire before playing our game in order to evaluate their initial cyber security and privacy awareness and knowledge. After being given the game to play across a week period, we will reevaluate the participants by repeating the questionnaire and evaluate the results. We expect that in conclusion we will find that players will have increased cyber security and privacy awareness knowledge as a result of playing our game.
- C44 - Path Finding, its Applications and a Comparison between its Many Forms
-

Michael Paterson, Luke Ibeachum
Supervised by: Radu Grigore
Project descriptionWe wanted to implement several path finding algorithms in order to study how they behaved. Our idea was to visualise the algorithms using a map as a graph, in this way we could identify the strengths and weaknesses of different algorithms and determine what applications may utilise the strengths of each algorithm.
We wanted to implement a UI for this project and doing so in Java, whilst not difficult would take too much time. After some discussion we decided to move our project over to Unity, this meant adjusting to C#. We also wanted to run the algorithms on a randomly generated map of Nodes instead of hard-coding a graph.
Our plan at this point was to implement several path finding algorithms on a tile-map and visualise the results by drawing the paths.
Results
Initially we created a small test using a hard-coded graph of Nodes in Java, on this we successfully ran Dijkstra’s Shortest Path and retrieved the shortest path. As mentioned though, we wanted a user interface and decided to move the project to the Unity Engine. Michael used Cellular Automata to create a two-dimensional array of integers (1s and 0s) which was used as a randomly generated graph. On this he implemented Depth First Search (DFS), Breadth-First Search (BFS), Dijkstra’s Shortest Path and two implementations of A* (Euclidian and Manhattan).
By collecting input, Michael made it so that a user can control the program, creating new maps, switching between algorithms and setting the start and destination points for the algorithms to navigate between. By changing the colours of tiles he was able to visualise the visited (explored) nodes, as well as the final path.
- C45 - Walking Zebra
-

Nnenne Ofochebe, Vaughn Sinclair
Supervised by: Dan Knox
Project descriptionWalking Zebra is a project that supports Hackington Parish Council. They are currently working to improve road safety in high-risk areas.
This project uses an IOT smart device to perform remote sensing and data communication. The device is able to detect motion from various distances. Our device also records the time of the detection. The data is transmitted via a low-powered radio network (LoRa) and then stored within a database. The functionality of the device was programmed in an event-driven programming language, Smart Basic. We also use Node-Red to manage the flow of our data between our remote devices and the database. We utilised two databases, Influx and Maria DB, as they achieve a perfect mix of functionality and usability.
Our smart device can produce data on human footfall in a given area; this would be useful for local councils. Additionally, our device provides analytical data about a location. Private companies could use this information to identify new revenue areas.
- C46 - Testing for Satisfiability using Backtracking and Learning
-

Leon Singleton
Supervised by: Andy King
Project descriptionMy project is designed to determine whether a given formula has a set of assignments which satisfy the formula as a whole. I plan to implement a basic DPLL based algorithm to determine a ground level of assignments, and then apply heuristics to determine sensible assumptions to be made as assignment. If an assumption fails, I’ll backtrack to before the assumption was made, but analyse my findings from having made the assumption and retain any information that is still useful and valid for further assumptions, backtrack notwithstanding. By retaining still valid information, I hope to improve the speed at which my program determines a satisfiable set of assignments, or at which it states that no such assignment exists.
- C47 - Incremental Cocke-Younger-Kasami Algorithm
-

Aelita Styles
Supervised by: Olaf Chitil
Project descriptionThe objective of the project is to alter the way in which the Cocke Younger Kasami algorithm verifies that a word is part of a grammar. Instead of rebuilding the parse table from scratch on each change to the word, it should find the changes in the word and only rebuild the table within the sections that would have changed. This should theoretically be more efficient with time.
Results
Currently the project consists of a partially working implementation of the extended Cocke Younger Kasami algorithm. It is able to find changed characters within a word and rebuild the table from that point, however it is currently unable to find when it no longer needs to continue. I have a few ideas on how to solve this particular problem, and I’m confident I will have a fully working solution by the time this poster is displayed. Based on current benchmarks, the program seems to be minimally more efficient than the existing solution. This is likely due to by suboptimal solution to resizing the table rather than the algorithm itself. I am in the process of implementing benchmarks to ensure this is the case.
- M1 - Bring Your Umbrella
-
Christopher Wood, Charlie Panayiotou, Ishan Jand, Krishnee Manikum, Thomas Taylor
Supervised by: Huy Phan
Project descriptionA Weather Forecasting application for the public to find out information about the current weekly weather forecast in their local area, providing appropriate weather notifications, e.g. when the user will need an umbrella. An additional functionality our application offers is displaying nearby supermarkets where they can purchase suitable accessories (umbrella, sunglasses etc.). The project should use an online service to retrieve data about the global weather forecast and the nearby supermarkets near the users’ current location.
Results
Our iOS application uses the user’s current geographic coordinates and the OpenWeatherMap API to display the weekly weather forecasts and the nearest 4 supermarkets. The application will display pop up notifications of daily weather data as well as accessory suggestions. Additionally, the user can create profiles for their friends to retrieve their weather information and send weather forecasts to friends through SMS/Social Media to help plan trips. Each user will have their own customised profile page which displays their personal information, a list of best friends and their most recent locations. The app dynamically displays a map with pinpoints to show their location, nearby stores and a link to Apple Maps for
- M2 - Expense Tracker
-

Lavana Dowler, Taieba Mehbuba, Bhavini Gajjar
Supervised by: Huy Phan
Project description
Create an expense tracker that people would be able to use on a daily basis. Enable them to keep track of their income and expenditure; allowing users to have a clear view of the different categories (shopping, food, travel, etc.) that contribute towards their expenses. A pie chart on the main page to show the monthly expenses, within the different categories. QR code, that would allow the user to scan the product which would automatically register within the reports/expenses. Other pages such as, FAQ and Profile page.
Results
Overall, we have created all the relevant pages needed, such as the login page, dashboard, income and expenses. The login page enables the user to login with their username and password, if wrong there will be a pop-up. The pie chart allows the user to view their monthly expenses within the different categories. The FAQ page will allow the user to view if there have any problems or questions concerning the app. The Profile page enables the user to view their information and also change their password if they like. As for the rest of the features, they are in progress.
- M3 - maxTime
-

Adam Davies
Supervised by: Yang He
Project descriptionUniversity departmental timetabling software, written in HTML, JavaScript and PHP using a MySQL database. Created to replace manual timetabling methods at department level; it assists the person assigned the task of timetabling for a university school by allowing them to create all the classes for a year which are then shown as icons in the timetable editor. These can be dragged and dropped into the timetable. Different terms can be selected and schools using bi-weekly timetables can create two timetables per term. Non-standard weeks such as project weeks can be added. Once the database has been populated in the first year, it can be continuously maintained making timetabling in subsequent years even faster. A previous year’s timetable can be loaded into a new year’s timetable and adjusted to quickly create a new timetable. Clashes and omissions are avoided and constraints are enforced, preventing errors and saving excessive overtime caused by mistakes.
Results
A fully working system has been implemented as a viable, marketable piece of software that complements whichever central timetabling software a university uses. maxTime is designed to be used prior to central timetabling and creates a consistent methodology for all schools rather than the variety of different methods that schools use to handle their own timetabling issues. On purchase, a member of the central timetabling team for the university has access to the supplied administrator account allowing them to create schools and this automatically creates a ‘timetabler’ account for each school. Within each school, the person who deals with timetabling uses the Timetabler account to collect all the data required such as modules, lecturers, classes and lecturer constraints. This collected data is then used to create the timetabling requests that are ultimately sent to central timetabling. maxTime is an excellent partner for any central timetabling system.
- M4 - Advanced Game AI
-

Alex Hey, James Morley and Robert Tucker
Supervised by: Matteo Migliavacca
Project descriptionFor our project, we implemented a neural network of our choice behind classic games. We chose NEAT (NeuroEvolution of Augmenting Topologies) to perform the machine learning section while using other libraries and Open Source code to implement both Breakout and Pacman.
From our study, we have successfully trained the NEAT network to be semi-competent in playing classic games. With Breakout, this consisted of following basic strategy and mirroring the balls X coordinate. With Pacman, a much more complicated game, it successfully worked out the optimum initial path as well as the best way to score points; eating the ghosts.
Results
During the training of Breakout, it was able to get a high-score of 261 (1 point per block break and -0.5 on death). During the training of Pacman, it was able to get a high-score by consistently avoiding ghosts while also taking the longest path across the board to the power pellets. Across both games that we trained our neural network on, the high-score fluctuated as we altered the different parameters and methods.
- M5 - Turing Chatbot
-

Atharv Garg, Swapnil Jha, Bethany Tye, Simon Baiden, Tom Colling
Supervised by: Anna Jordanous
Project description
Our Group wish to create an articulate chatbot which is able to converse with any given individual on a number of different topics. The Chatbot is built using the deep learning technique of Recurrent Neural Networks (RNN) in which a special type of RNN called LSTMs are used to store the long-term memory of the chatbot. The chatbot is trained using a conversational dataset (Cornell movie dialogues corpus) which needed to be pre-processed in order to be fed into our model. A Seq2Seq Model was used to train our chatbot which allows a user input to be encoded into an intermediate numerical representation. The decoder then takes this numerical representation and decodes it to generate a sequence of text as a response of the bot. We used the Pytorch Deep Learning library from Facebook to implement our chatbot. We also created an attractive website using HTML & CSS where we plan to host our chatbot using the Python-based web-framework Flask which allows us to integrate our chatbot model to the website.
Results
We have created a website for the chatbot and have pre-processed the data so that it can be fed into the Seq2Seq Model. We trained the Model on Google Collaboratory where we used Colab’s GPU for faster training. Having trained a bot on Colab, we now have a .tar file which contains our Seq2Seq model with the trained weights and biases, that can be called via a python script we modified. By calling the .tar file, we can talk to our chatbot via the terminal and have a relatively high-level conversation. We now need to improve the accuracy and get the bot to take about a wider array of topics. We will do this by feeding more data and improving the pre-processing techniques.
- M6 - Cracking the Turing Test: A Sarcastic Chatbot
-
Busayo Akeredolu, Devika Drubhra, Kavi Bhatt, Adam Williams
Supervised by: Anna Jordanous
Project DescriptionThe aim of our project is to build a chatbot capable of passing a simple Turing Test. The Turing Test is a test used to determine the extent to which a computer can imitate intelligent behaviour, similar to what would be expected of a human. It is a test that is yet to be passed by any known machine and our focus is on coming as close as possible to imitating the simplest human behaviours with our chatbot. We have applied Natural Language Processing, Text Analytics and Machine Learning to communicate with a user, analyse their input and generate responses to this as if they were speaking with another human. Our chatbot has been trained using sarcastic and humorous data to imitate these human behaviours.
Results
Evaluating our results and the effectiveness of our chatbot at achieving its aim is an ongoing process. At the moment, we have been able to decipher a user’s input and generate an appropriate response. We make use of an ‘Interrogator’ who acts as the tester. This person speaks with both the chatbot and another human (both unseen) and has to determine which is the human and which is the chatbot. We have been able to build a chatbot that gives answers that resemble a human’s and can simulate certain intelligent behaviours but only one out of four interrogators we have used has guessed the chatbot to be the human.
- M7 - Auto Email Reminder
-

Ricky Gohil, Henry Nwosu, Salman Al-Mohannadi, Kamil Bajwoluk, Olawale Jenkeo
Supervised by: Daniele Soria
Project descriptionThe aim of the project is to design and develop a Gmail automated add-on - using Google script - that sends frequent emails to specific recipients at a certain time until the recipient sends back the expected reply. Our audience are people who need to send frequent reminder emails, such as in a business or in an educational setting. We started the project by planning out the required steps, like gathering the functional and non-functional requirements. Before implementing anything, we had to familiarise ourselves with Google script. We’re using Google script to create the add-on so that it is directly integrated with Gmail instead of emulating the competition that relies on browser extensions. This also allows our app to be used on the mobile Gmail client, without requiring any extra development, providing flexibility for the consumer.
Results
Our projects purpose is to create an automated email reminder add-on that is flexible to work with. We made it configurable to re-forward an original email at a set given time, and the covering text can also be slightly changed. The add-on will scan the inbox to detect if a reply has been received, and it gives the user the ability to override the default behaviour (for example, to tell if “reply received” or to say “that wasn’t the expected reply”). We have provided a page where the user can view all the emails threads that are monitored. This should log the monitoring as well as present the dates in which reminders were sent and when the reply was received. The emails are stored on the individual’s Google Sheets account which means that they are the only one that can access it and thus maintains privacy.
- M8 - Gesture Control
-

Sergen Karaoglan, Alasdair Dewart, Aaron Ireson, Chengxi Yang, Owen Oliver-Wiley
Supervised by: Frank Wang
Our project objective is to allow users to control Chrome using an ordinary webcam with a Chrome extension. The extension has optional functions such as scrolling vertically or moving back and forward a page and the functions can be associated with any gesture of choice. This is all achieved by providing a trained convolutional neural network that can detect features of an image allowing the user to train fully connected layers connected to our convolutional deep neural network for classification using a dataset they can create by capturing images with their webcam on our extension. Once trained the extension will start using live webcam footage as input to the trained model to make predictions. We provide a user-friendly interface in which users can build, customise and train a model within a few clicks while automating processes such as labelling and pre-processing for the images they capture for their dataset.
Project descriptionResults
We have created an extension that successfully achieves what has been described. Tensorflow.js is at the core of our extension which has been used to create vital functions of our extension such as creating a model, building a dataset and training. As described the user can also customise hyperparameters which are learning rate, number of units in the hidden layer, number of epochs and batch size. Our next objective is to provide more options to the user such as being able to export and import a trained model and more browser functions while still maintaining a user-friendly interface. Our other objectives include improving the performance of the model by implementing and testing alternative methods to train and pre-process.
- M9 - Scientific Research Calculator (SRC): Web Application
-

Ashley White, Daniela Miteva, Fardusa Jibril, Modestas Garkevicius, Simran Mattu
Supervised by: Fernando Otero
Project descriptionOur project was inspired by an existing web application, “The Single Case: TAU-U Calculator”. The calculator is designed to aid researchers to record and manipulate from large data sets, this application had numerus downfalls which made its use impractical. The main issue we found was that the user was unable to save their inputs and findings, as well as uploading and downloading of files. The biggest concern was the lack of error handling features.
We chose to implement this project as we felt that the project was able tie in all our previous knowledge as well as challenge our skills. We found the concept of the TAU-U likable and a great baseline for the project.
Our design is an enhanced and more complex version inspired by the TAU-U calculator, we were able to implement the features that were missing from the existing application, the biggest challenges we faced were learning about local storage in html 5 and applying it as well as manipulating JavaScript for the upload/download button.
Results
Upon reflection of the project, our new and improved version of this web application brings many new features which have been requested by current users. The new features consist of allowing the user to locally save data, therefore, when the user reopens the application, the data is stored until its manually cleared, making it simple and convenient.
Furthermore, we have added features to allow the user to upload data in a CSV file format or manually entering data. In addition, data can be specifically selected to compare and produce visual results in the form of a graph. The application incorporates branches of JavaScript in HTML 5 (jQuery and JSON) to obtain a unique site which allows the user to have a trouble-free experience whilst using the multi-functional SCR tool.
Features such as downloading of raw and processed simplifies the process making it a user-friendly experience. Lastly, we have added additional features such as calculating of averages such as mean, median, mode, range and standard deviation to bring users much needed flexibility.
- M10 - SchedulePro: Student Timetabling System
-

Temitope Sorinola, Jacob Coventry, Regina Gonsalves, Michael Holden
Supervised by: Dr Yang He
Project descriptionSchedulePro is a revolutionary event scheduling application that is developed to ease the ever-busy lives of everyone such as students, teachers, administrators, and professionals from all walks of life. It is accessible on a variety of bowsers from which students and staffs would be able to view their timetable in a day, week, month and year format.
Results
SchedulePro application enables an administrator to edit both students and staff’s data, add data to the database and delete both staff and students data from the database while it updates the database to reflect information in real time. The application displays both student and staff timetable in relation to the taught modules, time slots and the locations where the modules are being taught alongside the details of the lecturers teaching the modules. By selecting a particular module on the timetable, the app automatically navigates user to the information about the module via a web link. Staff members can send messages to the administrators to request for event booking or cancel an already booked events. The app was developed using modern Web Technologies such as JavaScript, PHP, CSS, Bootstrap, HTML, PostgreSQL and Web API in the form of Json.
- M11 - Financial Analysis Data Tool
-

Marvin Cooper, Dylan Osei-Bonsu, Gahie Okou, Daniel Bright
Supervised by: Michael Kampouridis
Project descriptionQuickAnalysis is a website design to give fast, clear and simple analysis on ten popular stocks. The aim of the website is to facilitate easy use for the users to find simple and effective analysis on ten of the most popular stocks.
Results
By using a scraping tool to get information off Yahoo Finance for the ten stocks we chose, (Apple, Google, Microsoft, Tesco, Gold, Oil, Copper, HSBC, Lloyds Bank and Barclays). We created a website to display the information and current stock prices of these chosen stocks. The website also contains relevant news articles pertaining to these stocks so that users can be updated on news that will affect the stocks. The website will also give our analysis on these stocks so that users can effectively asses for themselves the trend of the stocks. Overall, the website is designed to create a user-friendly platform for viewing stocks with relevant but easy to understand analysis of them.
- M12 - Neurik
-
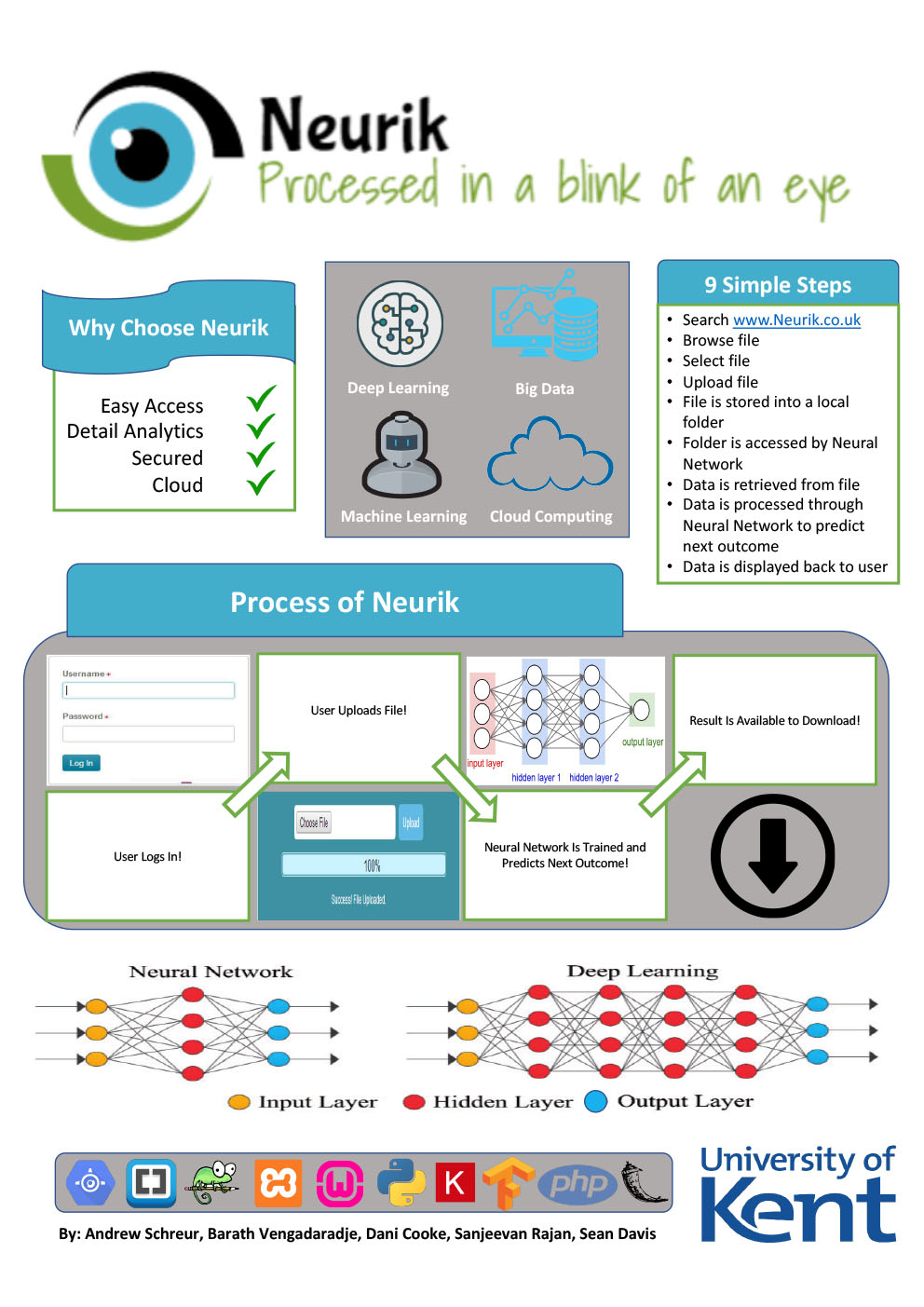
Dani Cooke, Sean Davis, Sanjeevan Rajan, Andrew Schreur, Barath Vengadaradje
Supervised by: Frank Wang
Project descriptionThe aim of this project is to provide easy access to the power of neural networks and deep learning without requiring the user to have knowledge of data science or machine learning. Users can upload labelled datasets to Neurik, which are then used to train a supervised neural network; upon completion of the training, users can then upload novel unlabelled data and receive classification predictions. Throughout this process the user does not need to worry about details such as the number of hidden layers or the node count, as these are configured automatically by the service. Neurik will be hosted on a cloud computing service to allow it to scale with the varying demand as well as removing the need for upfront hardware investment.
Results
Neurik has been created as a website that provides zero-configuration access to neural network training and classification, built with the Tensorflow package of Python. Users can upload single datasets as anonymous users, accessing the results through a unique link, or sign up to see and manage all of their models. Neurik can be trained on arbitrarily large files, both in terms of feature number or sample size. Using the automatic scalability of the Google App Engine on which the backend neural network is hosted, the training speed is unaffected by the traffic/popularity of the service, while keeping costs to a minimum in times of low use.
- R1 - Statistics on the Use of Different Password Policies by Websites
-

Alexandru Dragan
Supervised by: Shujun Li
Project descriptionPasswords are the main authentication method throughout the web. Whether you’re logging in to order a pizza or you want to check your bank account, you’ll need to prove your identity via passwords. However, all of these different websites may have different password policies in order to increase security or prevent spam. This project aims to identify patterns between the policies used by websites, as well as which websites use which policies and why. The whole process is done via web automation (Selenium WebDriver) to crawl a collection of websites gathered from search-engine results using various key-words. Specifically, the things we look at are whether we can copy-paste passwords, the presence of password meters and captchas, the presence of password hints on login and the password composition policies where possible. SQLite is used to aid in the storage of data.
Results
Based on the current data gathered so far from websites (n: 300), I found out that about 98% of websites allow the pasting of passwords into the password field. The ones that do not, are military / government related websites and a couple of insurance companies.
The presence of password meters sits at 12%, while captchas are present in about 39% of the websites. Captchas are mainly used to prevent spam, but another way of preventing spam that some websites also use hidden fields (also known as honeypots) to prevent form spam. If the hidden field is completed by a bot / crawler, it can be detected as spam and rejected, as I have found out on certain websites while gathering data.
Interestingly, a lot of websites do not provide many details on registration regarding password composition initially. No instructions are given to minimum length, lower or upper-case, or alpha-numeric requirements, unless you fail the registration process at least once.
- R2 - Hiding Information in Digital Activities
-

Callum Hood
Supervised by: Prof. Shujun Li
Project descriptionThis project is about developing a prototype of a new information hiding framework recently reported in the research paper of my supervisor (Li et al. 2018, https://doi.org/10.1145/3267357.3267365), which will be an Android app based on a previous prototype that can allow secret information to be covertly communicated between a sender and a receiver in the form of encoded digital activities on multiple online platforms. Two such platforms, the online social network Twitter and the image sharing service Imgur, are used as examples. Twitter will be used to communicate secret messages and used as a covert command & control (C&C) channel to indicate secret messages hidden in images on Imgur. The project will also involve analysing the security of the implemented information hiding method and a user acceptance test is planned to verify the usability of the app.
Results
The previous prototype can only hide short messages as retweets on Twitter via the C&C channel. The new app has added Imgur as a new information hiding platform, extending the information hiding capability by introducing an additional method of steganography – image-based steganography – to increase its security and usability. A message is first encoded into a suitable cover image – either pre-determined or programmatically selected – and uploaded to Imgur, generating a URI which is communicated across the C&C channel (Twitter) as digital activities (tweets and retweets). This improves security as the image is hidden from the public and can only be accessed by use of the URI – a greater security analysis has been performed for the report. A usability analysis of the app has been performed to determine how the faster encoding rate (and UI improvements) affects the general user experience.
- R3 - Malicious Firefox extensions based on AJAX
-

Kieran Richardson
Supervised By: Shujun Li
Project DescriptionWeb extensions pose a very real and very significant security threat, but just how many extensions take advantage of the lack of security isn’t yet known. In my research I look at web extensions and their XMLHttpRequests, and what sorts of extensions are more likely to be malicious. I web-crawled across the Firefox web extension store, gathered all of the extensions that Mozilla recommends and analysed them using Python scripts. A limitation of my methodology is the fact that more malicious web extensions are most likely not on the Firefox web extension portal, they would more likely be somewhere else on the clear web.
Results
The results are dependent on the reader’s definition of malicious actions. For example, some may consider background data collection for analytics to be malicious, whilst others may consider part and parcel of web developing. I have considered this and have decided to note what the source of “malicious” behaviour was, be it data collection or keylogging, so the reader can make their own opinion.
The results showed that a lot of popular web extension developers do not add malicious code to their projects, despite the potential for doing so being there. This is most likely because if they had bad press over being exposed once for adding malicious code then their company would take a massive loss in earnings.
This concludes that although the potential is there for malicious developers to steal data, most refrain from doing so, although this conclusion was based only off of 78 extensions.
- R4 - Finding the Answers to your Security Questions using the Internet
-

Lily Calnan
Supervised by: Jason Nurse, Shujun Li
Project descriptionKnowledge based authentication, such as security questions, have been a commonly used method for two factor authentication and credential recovery for many years. However, many web platforms including social media, discussion sites and microblogging sites have allowed users to share information more freely and in many cases publically. Much of the information that these platforms allow, or encourage, users to share seem closely linked to that used to build security questions.
In this project, I investigated the link between information that is used in knowledge based authentication and that shared by users on the internet and whether this could allow these questions to be bypassed.
Results
The results of this project showed that there is some connection between certain security questions and information users publically share. This information usually covered very non-unique and less personable things such as the user’s first job, first car, first pet’s name, or favourite book. This set of questions could be seen as being less secure in this case as they are easily discoverable and in certain cases can be easily bypassed.
For a number of questions there was, however, no substantial link. This shows that at least a reasonable number of the data set could be seen as not being easily discoverable at, least on these platforms. However, with more data gathering and analysis a clearer link could be found.
- R5 - Passwords in 3D worlds
-

Sarunas Valiulis
Supervised by: Shujun Li
Project descriptionPassword is a really important part of modern world everything is digital. It is crucial to find a way to create strong and easy to enter passwords. Typically used passwords are text-based passwords, but for text-based password to be strong it must be long and hard to remember to prevent dictionary attacks. So, to combat this issue we decided to explore the idea of 3D password where the user can enter 3D game like environment where it is able to explore the world and authorise itself by performing sequence of actions into the system or game itself. That way we can use 3D games to increase the password space. 3D Game chosen is Minecraft duo to its flexibility and its’ environment richness to facilitate 3D password. The mod created using Java. Research focus is to prove feasibility, usability and security of 3D password by creating prototype and testing it.
Results
Our implementation of 3D password (that has never been implemented before that we know of) is feasible, usable and secure, however further user study is needed to better understand the level of usability and security. The user can create his/her own profile by selecting a username and a colour of the login block. Our calculations show great improvement in password space compared to textual passwords. The user can set the password in an easy manner also as change it at any time with couple of clicks. Furthermore, the user can recover from errors by using backspace as would with typical password. Whole time user is indicated what is going on. Lastly it is possible to combine more than one authorisation type. Our implementation supports text-base, actions-based or a combination password. 3D password could be combined with biometric or any other type of authentication in the future.
- R6 - Machine Learning for Uncertain Biological Data
-

Jack Saunders
Supervised by: Alex Freitas
Project descriptionMachine learning can be used to discover new patterns in data about complex biological processes. However, data in biology often involves a degree of uncertainty that can lead to misclassification and fallible data models that misrepresent the impact of certain classes of instances. This project has looked at datasets of ageing-related genes where class labels have differing degrees of reliability when they represent the role of a gene in the ageing process. Each gene’s class label is defined by the type of evidence we have that that gene is related to the human ageing process and is a nominal value of either “human-mammal” (our ground truth) or a weaker type of evidence for a role in ageing. Genetic algorithms have been developed to handle the data at a preprocessing phase and learn the weights that best represent the degree to which a class of gene influences the human-mammal ageing process. An instance-weighted random forest model is then built and tested through ten-fold cross validation.
Results
Within the cross-validation, the data was divided into training and testing sets as usual, and the training set was further divided into learning and validation sets. Four different versions of a genetic algorithm were developed to handle class imbalance, each varying the class distribution in our learning and validation set, and our training set. Versions 3 (balanced learning and validation set, imbalanced training set) and 4 (imbalanced learning and validation set, imbalanced training set) have been shown to produce the best predictive performance on each dataset, measured by precision, recall, and kappa statistic. The class weight results show that three classes, being downstream, functional, and putative, were assigned high weights across folds and datasets, indicating that they have a high influence on the human-ageing process, whereas others, such as human link, were inconsistent across experiments, signifying that they have minimal impact on classification.
- R7 - C to Java via CIL
-
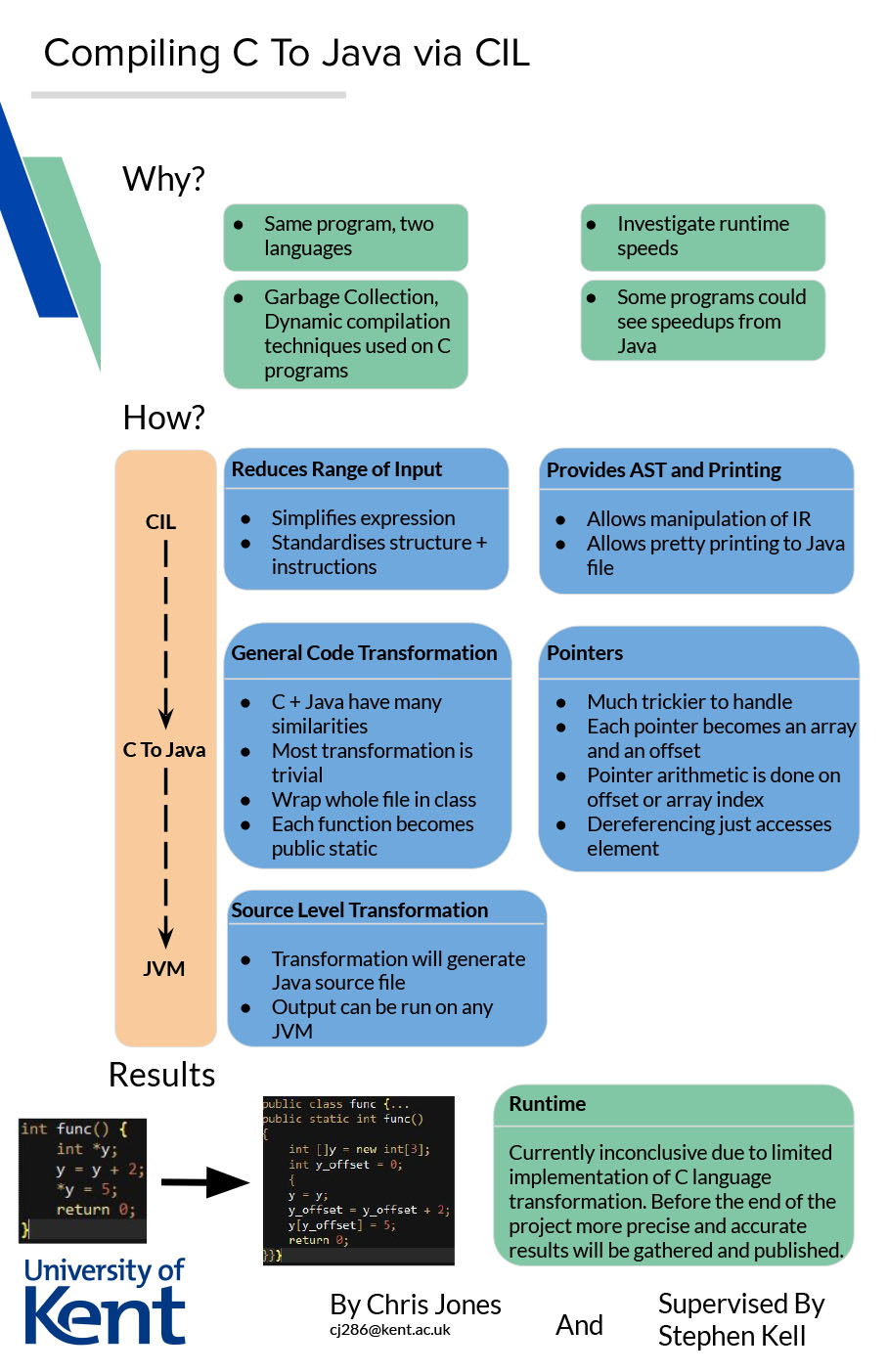
Christopher Jones
Supervised by: Stephen Kell
Project description
C is a memory unsafe language, with no garbage collector or runtime checks on memory accesses, that suffers from large slowdowns when instrumented to be used safely. In contrast Java, a memory safe language that does perform runtime checks, can often run at speeds roughly competitive with C, due to a lot of effort put into many dynamic compilation techniques and its garbage collector. In this project I explored and modified the third party, intermediate language CIL to include my own ‘C to Java’ pass. CIL was used to make modification and printing of C code feasible. C to Java performs a pass to print out the newly generated Java source code which is finally compiled by Java and run on a JVM. I then investigated the runtime speeds of this code and compared it to the same instrumented, original C program also run through CIL and compiled by GCC.
Results
Currently C to Java is implemented to transform a small subset of C which includes pointers and pointer arithmetic. Current results seem to suggest that there is a significant runtime slowdown when running on Java compared to uninstrumented C. Due to the current limited implementation and the additional warm up time that Java needs that C doesn’t, it is challenging to gather meaningful results from this project. This makes it likely that if the subset of C can be increased and the warm up times removed from the data then these results could change significantly. Before the end of the project I aim to extend this subset to increase the number of programs that can successfully be transformed and thus tested. After this project is finished future efforts could be put into extending the subset to handle real C codebases.
- R8 - Machine Learning for Predicting the Side Effects of Medical Drugs
-

Cohen Wisbey
Supervised by: Alex A. Freitas
Project descriptionIn this project, we propose a new variation of a machine learning method for predicting the side effects of medical drugs. We utilised a type of classification method called Rule Induction, which builds a model based on "IF condition THEN class" rules, where the conditions indicate presence or absence of drug properties and the classes are drugs' side effects. The RIPPER algorithm was modified to build rules with conditions indicating only the presence of drug properties, in order to discover more meaningful rules (the presence of a property is more informative than its absence). The binary properties include drugs' clinical indications and compound-protein interaction (CPI) probabilities that were binarized using a probability threshold. This threshold has been optimized in order to improve predictive performance. We also utilised ensemble learning, building multiple classification models (rule sets) in parallel and combining their class predictions using majority voting, again to improve predictive performance.
Results
Results have shown that the variation of the RIPPER algorithm does have some viability. In some cases (side effects), it would outperform the unmodified RIPPER algorithm on common performance measures, such as F-measure and AUROC (Area Under the Receiver Operating Characteristic curve), and other times it wouldn’t; this is true for both the CPI and Indication datasets. Regarding ensemble learning, running even as low as 10 iterations (bags) resulted in approximately a 10% mean performance improvement from standard RIPPER. More experiments are going forth to discover the performance differences on higher-iteration ensembles, such as 50 iterations.
- R9 - Quantum Cryptography – Security for the Post-Quantum World
-
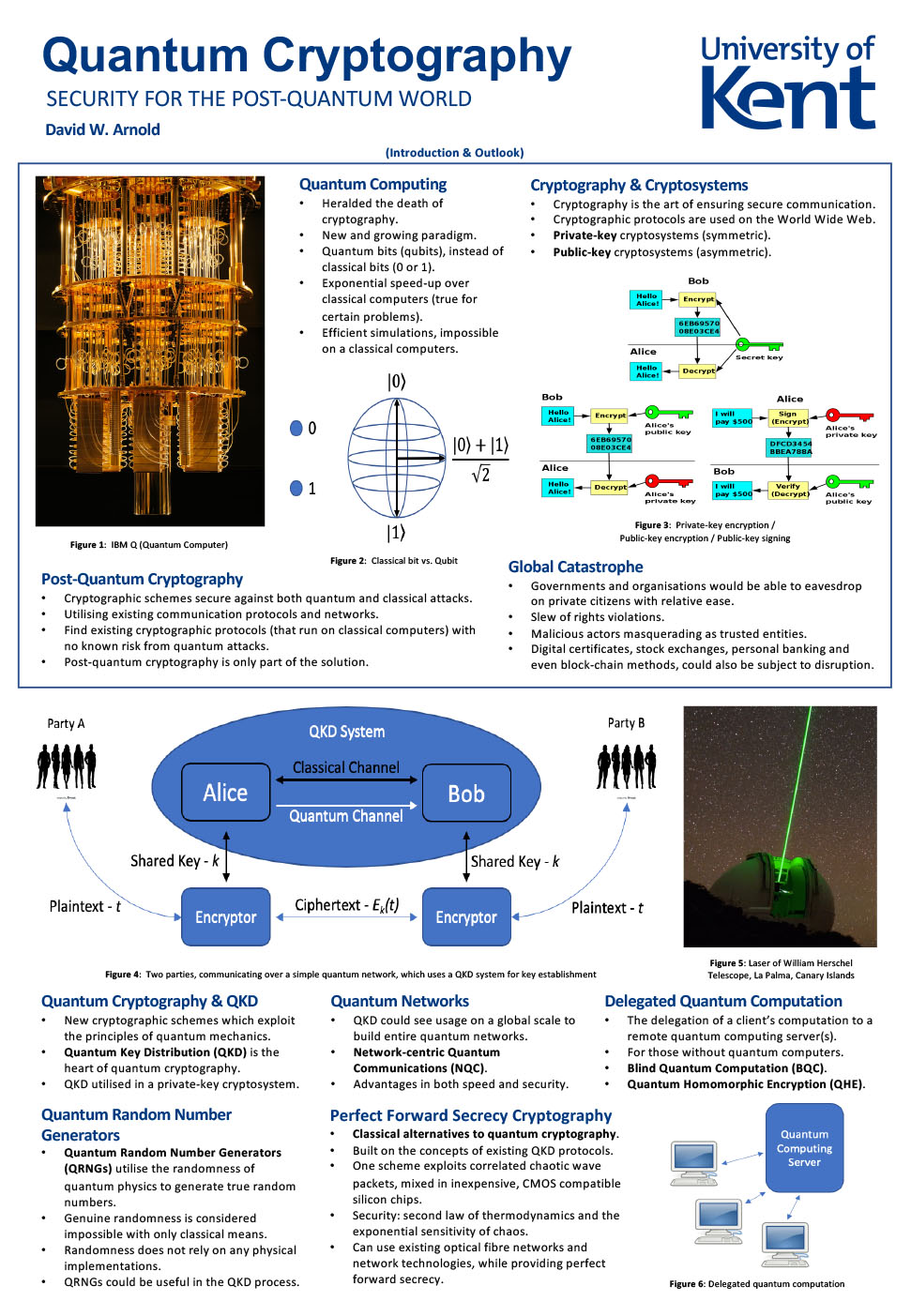
David Arnold
Supervised by: Carlos Perez-Delgado
Project descriptionQuantum computing has been heralded by some as the death of cryptography. Cryptographic protocols are used extensively on the World Wide Web, with many at risk of quantum attacks from forth-coming quantum computers. The Rivest–Shamir–Adleman (RSA) protocol is just one public-key cryptosystem at risk. Post-quantum cryptography provides a short-term/cost effective plan to counter quantum attacks, with the goal being to develop cryptographic schemes secure against both quantum and classical computers, while utilising existing communication protocols and networks. Society needs to be pre-emptive, as all the while existing cryptographic protocols are at risk of quantum attacks, there is risk of mass eavesdropping on citizens with relative ease by harnessing quantum computation, potentially resulting in a slew of future rights violations. Quantum cryptography is a long-term/more costly option, providing new cryptographic schemes which exploit the principles of quantum mechanics to enable (provably) secure distribution of private information.
Results
Quantum Key Distribution (QKD) is the heart of quantum cryptography, providing a means of key establishment for a private-key cryptosystem. Quantum Cryptography also concerns several other closely related concepts: quantum networks and network-centric quantum communications comprising of multiple trusted repeaters linked together by optical fibre/ground-to-satellite communication; Quantum Random Number Generators (QRNGs) providing true randomness; and delegated quantum computation techniques such as Blind Quantum Computation (BQC) and Quantum Homomorphic Encryption (QHE) providing access to quantum computation without having to own a quantum computer. QKD has also inspired new classical cryptographic schemes which draw on concepts from existing QKD protocols, such as BB84. One particular scheme, heralded as a classical BB84, conducts classical key establishment for a private-key cryptosystem and allows: implementation on existing optical fibre networks at a fraction of the cost of new quantum hardware, utilisation of existing network technologies, and provides perfect forward secrecy.
- R10 - Investigating the Efficiency of Unsupervised Learning in Spiking Neural Networks
-

Abigail Pattenden
Supervised by: Dominique Chu
Project descriptionSpiking neuron models are being increasingly explored for their ability to efficiently model complex behaviours with smaller networks of neurons, however few efficient training algorithms exist for spiking neurons in unsupervised scenarios.
In this project, I investigate the behavioural properties of spiking neurons when subjected to unbiased input data and aim to explore the relationship between the neuron’s learning rate and initial state of the model.
For the investigation I use a single Leaky Integrate-and-Fire (LIF) neuron, with synaptic weights that are updated by Spike-Timing-Dependent-Plasticity (STDP) in discrete time. The initial values for the synaptic weights are varied between runs, and I record synaptic weight update behaviour over the runtime of the neuron. I consider the values that each weight takes for the duration of the input period, and for how long the average fluctuations remain at a particular value.
Results
Results show that the synaptic weights remain in temporarily-sustained states of varying strengths, and that not only does the meta-stable state value appear to change in line with changes in the initial weights, but also that synaptic weights ‘swap’ in and out of these meta-stable states. The meta-stable state behaviour can be observed for varying numbers of input weights and varying initial values for these weights.
- R11 - Alexa, Is This A Mood? An investigation into the Effects Voice User Interfaces Have on Mood Tracking
-

Brandon Okeke
Supervised by: Dr Jason Nurse
Project DescriptionThe motivation of this project is to see if voice user interfaces could be a viable way of supporting an individual’s mental wellbeing, as well reviewing any possible caveats within the development of these tools. Conversational agents have been shown to be an effective way of delivering cognitive behavioural therapy (CBT), however, research that looks into commercial applications such as Woebot, often focuses on a text-based interaction. Companies who provide platforms for developers to create applications for their voice assistants are now benefitting from neural text to speech technology to create more realistic responses. There’s also currently a growth in the usage of voice assistants worldwide suggesting we are becoming more adapt to interacting with computers via our voice. This poses the discussion on if a voice based conversational agent could be used in clinical settings to administer CBT for patients who require a basic level of support.
The study involves the development of an Alexa skill and a basic mobile app. Both apps will mimic core features derived from the analysis of popular, commercially available mood journaling apps found on the App Store. The mobile application will be used to generate the control data. Before using either application, participants will be required to take an emotional intelligence quiz. The quiz will be repeated after using the Alexa skill to determine if there were any notable benefits to tracking one’s mood via the voice assistant. Participant will be split into two groups, each using a different medium first for a week, before switching to other, to avoid potential order bias. Usage statistics between the two apps will be compared and analysed alongside participants’ reported experiences of using the Alexa skill.
- R12 - Tracking the Trackers: Developing Tools/Methods for User Insight into Tracking
-
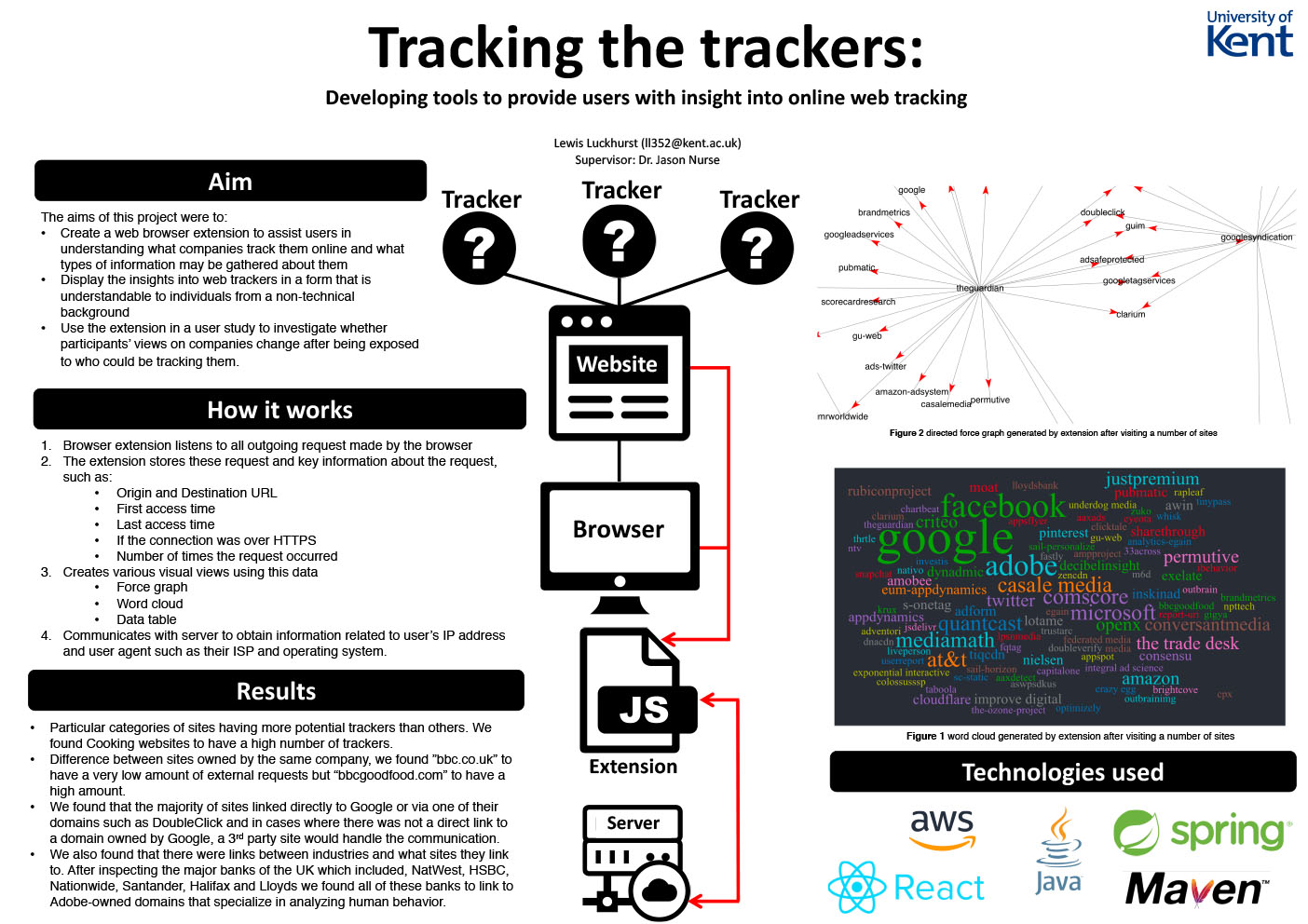
Lewis Luckhurst
Supervised by: Dr Jason Nurse
Project descriptionThis project aims to create a web browser extension to assist users in understanding what companies track them online and what types of information may be gathered about them. Display the insights into web trackers in a form that is understandable to individuals from a non-technical background. To use the created extension in a user study to investigate whether participants’ views on companies change after being exposed to who could be tracking them.
Results
The primary results for our project will come after we have completed a human study using the extension. We found that companies may differ their outgoing requests drastically across their different sites a prime example of this was “bbc.co.uk” and “bbcgoodfood.com”.We found that the majority of sites linked directly to Google or via one of their domains such as DoubleClick and in cases where there was not a direct link to a domain owned by Google, a 3rd party site would communicate with a google owned site. We also found that there were links between industries and what sites they link to. After inspecting the major banks of the UK which included, NatWest, HSBC, Nationwide, Santander, Halifax and Lloyds we found all of these banks to link to Adobe-owned domains that specialize in analyzing human behavior.
- R13 - Pattern Matching Modulo Theories
-

Declan Barnes
Supervised by: Dominic Orchard
Project descriptionThis project looks to improve the pattern matching facilities of the Granule programming language by making use of an SMT solver. This has two aims: automatically generating valid cases for a given variable, and expanding which pattern matches can pass the typechecker. We develop a method for case splitting which generates potential patterns for a set of variables. This functionality is inspired by the Agda language and uses the same syntax, though the SMT solver allows splitting to succeed in cases where Agda’s unification fails. This functionality is complemented by an automatic rewriting system which transforms source files containing holes. We also develop an algorithm for propagating theorems from failed pattern matches to the relevant parts of later patterns, this gives the SMT solver more information when evaluating a pattern’s validity, allowing it to accept well-typed definitions which would be rejected if the pattern was considered in isolation.
Results
The application of satisfiability to case generation is successful in eliminating impossible cases, allowing complex indexed types to be split, with the generated candidates adhering to the constraints of the type. As well as this, programs can be automatically rewritten by passing a flag to the Granule interpreter, this functionality was then embedded in a simple editor extension, to allow interactive development using holes.
- R14 - Vulnerabilities in Messaging Apps to Quantum Attacks
-

Samuel Clark
Supervised by: Carlos Perez Delgado
Project descriptionWe know that some cryptographic primitives used today are compromised by quantum attacks, which are in use in some of the most frequently used applications around the world.
In this project, we aimed to look at some of the most popular messaging apps used today and analyse the cryptographic primitives used within them to see which apps are vulnerable to quantum attacks. This includes the security systems used in authentication, key exchange, digital signatures, and any other encryption that may be used in the messaging app.
We took 10 of the most popular messaging apps used today, with documented cryptographic primitives, and looked at the potential quantum attacks. We were then able to determine how much of a vulnerability it causes for the application. Some security measures used in the applications may be vulnerable but be used behind a more secure algorithm that reduces its vulnerability.
Results
We were able to learn about the different cryptographic primitives used in the applications and even found that some technologies used are vulnerable to classical attacks such as SHA-1.
A large majority of the messaging apps use AES-256 encryption, for encrypting the plaintext, which isn’t fully vulnerable to quantum attack but slightly weaker against a quantum attack (using Grover’s algorithm) compared to an attack using a classical computer. AES-256 is still considered a feasible standard for encryption even due to a quantum attack.
Certain apps used RSA, for signing messages, which is vulnerable to quantum attacks using Shor’s algorithm. The consequences of this are that if a quantum attack is used it can create an uncertainty whether the message is sent from whom that say they are. This is also the same for elliptical curve cryptography (ECC) which is used commonly in the messaging apps for establishing a secure key.
- R15 - Exceptions in a Linear Functional Language with Graded Modal Types
-

Rowan Smith
Supervised by: Dominic Orchard
Project descriptionGranule is a language developed for research in combining linear, indexed and graded modal types in functional programs. This project extends the Granule language to support the handling of exceptions. Exceptions may occur in any program with side-effects, whereby inconsistencies are created by altering data in the environment outside the program. These can be 'caught' and 'handled' such that the program can progress as if an exception did not occur. The Granule language does not currently implement any handling of side-effects. As it emerges from the realm of the strictly functional with a limited set of operations on files, a mechanism to handle these resulting exceptions is necessary. Exceptional branches violate linearity as resources should be used exactly once. This project examines the typing, reduction and propagation of exceptions in a linear environment by leveraging graded modal types.
Results
I have extended the Granule language with exception primitives and a top-level construct to handle exceptions. The grammar has been extended in the lexer, parser and AST, type-checking now holds for exceptional types and the interpreter is able to evaluate exceptional expressions according to operational reduction rules. I have updated the normalisation/approximation according to type equality rules and all utility/helper functions that compute over expressions. Test examples have also been included.
- R16 - Usage and Structure of Continuous Integration as Configuration
-

Joseph Ling
Supervised by: Stefan Marr
Project descriptionLooking at how continuous integration (CI) is used and then the structure of that configuration. As CI is becoming more popular looking at how it is actually used as it’s very easy to get a surface look at one type of CI. But now each specially as major version control hosting platform is getting their own CI system with its own configuration setup is difficult. As well as there is not too much research in this area recently. In order to tackle this problem, we scrapped repositories using Github’s public API in order to gather what CI’s people are using. Then processed the results with tooling created for this project.
Results
After creating a sample of around 30,000 repositories from Github the first step was to filter out all the ones that didn’t have CI. Then for those that did look at if there were any factors for a repository that increased the chances of it having CI. In doing allowing us to analyse the factors to help workout who used CI more. After that looking at the actual CI files and analysing the structure. This led to us finding that comments are rarely used in CI files despite who large and complicated they can get. Finally, a lot of work has gone into making all the results a 100% reproducible. For example, as new repositories from scraping are added the whole report and with graphics are reloaded with that new data.
- R17 - Type-Level Case for Lightweight Dependent Types in Granule
-

James Dyer
Supervised by: Dominic Orchard
Project descriptionGranule is a statically-typed functional programming language under development which demonstrates various types currently being researched (Orchard, Liepelt and Eades III. 2019). One notable type is the Session type as in (Yoshida and Vasconcelos 2007), however Granule lacks support of the external choice operation. This project extends the syntax and type system of Granule to accommodate switch statements on the type level to remedy this lack of support, and to make the type system of Granule more expressive.
Results
The type system of Granule has been changed as a result. A type-normalisation step has been added during type-checking, so that switch statements correctly reduce when the guard is known. Previously during the type-checking process, the type substitutions generated were combined and all applied to the type at the end. However, type-equality operations required that types be in their normal form, so substitutions are now applied to the type progressively as they are found, after which the type is normalised.
In addition, the representation of Types and Kinds was unified as a Universe Hierarchy (Ulf 2007). This was to reduce code duplication on the Kind-level, as similar operations were already being done on the Type-level. This has resulted in Type-level case being usable at any universe level, so programs that apply switch statements on Kind-level and above are now also possible.
- R18 - A Framework for Behavioural REST APIs
-
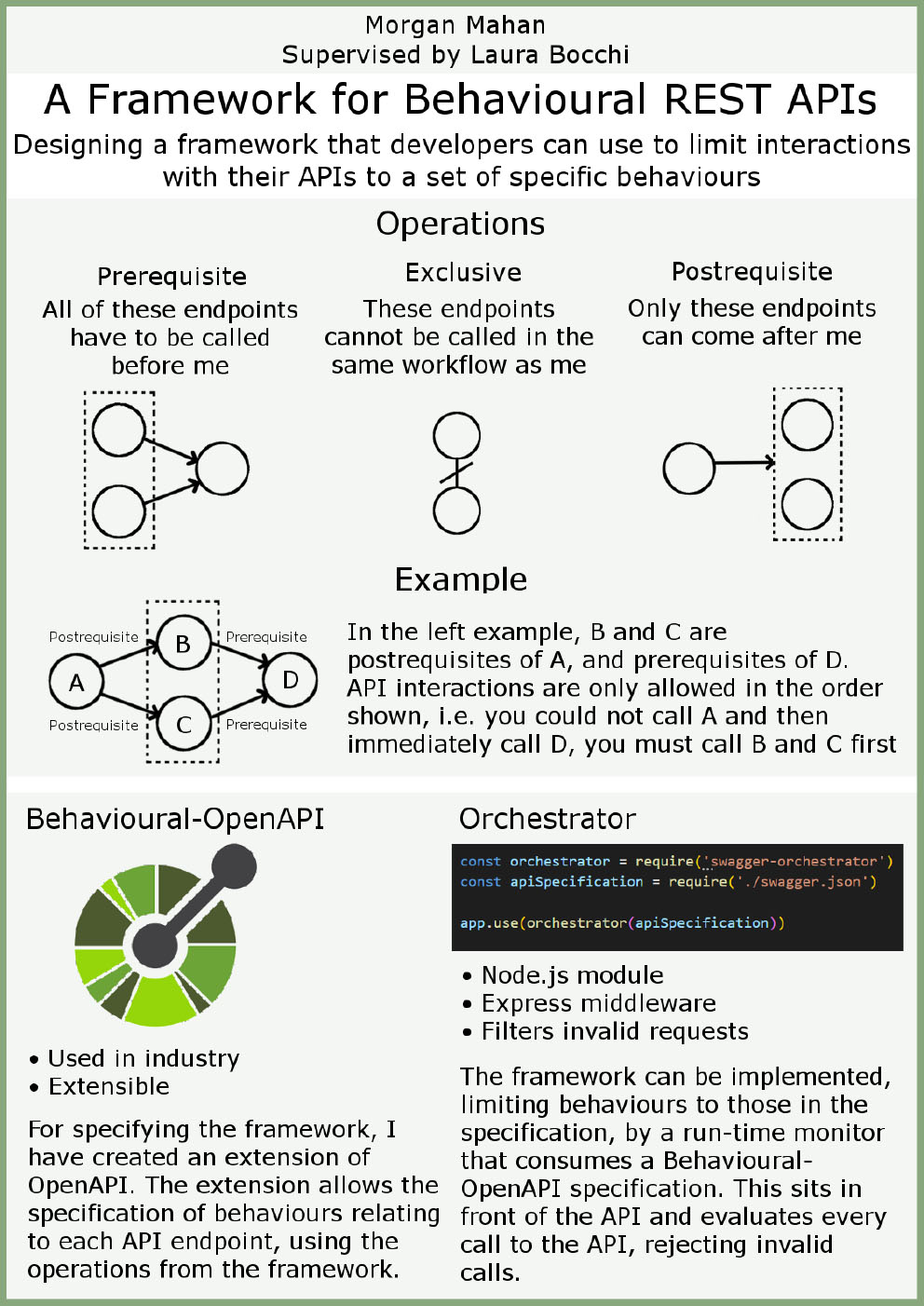
Morgan Mahan
Supervised by: Laura Bocchi
Project descriptionBehavioural REST APIs often need particular behaviours to occur in a particular sequence or workflow, but this is often not documented, being enforced by developer knowledge alone. Constraining API interactions to desired behaviours ensures that the API can only be interacted with in a valid sequence. Currently, there is no API description format that includes behavioural information. Having a REST API specific workflow description format allows behavioural information to be included with other API documentation and allows the generation of tools that can govern API interactions based on the API description, such as a run-time monitor for API interactions. Interactions with an API can then be forcefully limited by an orchestrator service that sits in front of the API, restricting out of sequence calls. This ensures that API behaviours are limited to only those that are desired.
Results
A framework consisting of three operations, pre-requisite, post-requisite and exclusive, allows each API endpoint to specify its relation to other endpoints in a way that allows detailed specification of API behaviour and allows for a simple specification format. This has been integrated into Swagger’s OpenAPI, an extension that is being called Behavioural-OpenAPI. To forcefully limit API interactions to those allowed by the specification, a Node.js module known as Swagger-Orchestrator has been created to be used as server middleware, rejecting API calls that are not part of a workflow specified in the Behavioural-OpenAPI specification. Both OpenAPI and Node.js are heavily used in industry and Swagger-Orchestrator has been tested with Express.js, the standard server framework for Node.js, ensuring that the framework could easily be applied REST APIs in industry.
- R19 - Brain-Like Networks of Neurons
-

Maximilian Harazin
Supervised by: Dominique Chu
Project descriptionIn this research project, I am trying to look at randomly generated networks and specifically, networks based on the Watts–Strogatz model as those appear to exhibit a small-world property, I compare these networks to regular, or ‘lattice’ networks, as well as fully random networks to see how the chosen measurements change as a network approaches higher randomness.
The metrics I look for will include the average shortest path and the average global clustering coefficient. I will also look into how these metrics change in regards to time complexity and whether the shortest path grows logarithmically with the size of the network.
In the final part of the report, I will discuss how the data gathered relates to ANN’s and machine learning and the research that still needs to occur in this area.
Results
The results will mainly be the values of the average shortest path and the clustering coefficient, though other metrics may be mentioned too. The outcome should be the data of how these metrics change as the network randomising probability (p) increases.
We can predict that the networks are each going to behave in a predicted way, such as the average path getting shorter in more random networks and clustering being higher in more ordered networks. But the results will give us accurate values for both of these measurements across different sizes of networks.
Since results are going to be gathered from different network scales, we’ll be able to see if the size of these networks makes a difference. It’s expected that the average shortest path will grow logarithmically with the network size, and the clustering will be affected more by the randomness of the network rather than its scale.
- R20 - Fairness-Awareness Algorithms in Machine Learning
-

Eugene Potter
Supervised by: Alex Freitas
Project descriptionMachine Learning algorithms are increasingly entering systems used to make decisions that have significant impact on people’s lives. These methods aim at extracting interesting knowledge (or "hidden patterns") from real-world data. As a result, the application of such algorithms to real-world data (particularly data about people) often leads to predictions which have a good predictive accuracy but are unfair, in the sense of discriminating (being biased) against certain groups or types of people; characterized e.g. by values of attributes like gender or socio-economic attributes. Here we seek to solve these problems through a fairness-aware data pre-processing technique called ‘data massaging’, which reduces the degree of discrimination in the data before passing the data to a classification algorithm. Here were taking into account the trade-off between achieving high predictive accuracy and a high degree of fairness. The project studies this kind of trade-off, ultimately evaluating how effective the data massaging technique is for improving fairness whilst not substantially reducing predictive accuracy.
Results
Results for discrimination showed that before the massaging technique was applied all data sets returned mildly positive discrimination scores. With each relabel application we saw changes in the data with visible changes in discrimination scores. However due to the distribution of relabels and application, a 0 discrimination score was never reached within the sets. We also saw that as we ranged into 80% to 100% application, trends of strong reverse discrimination appeared. All categories for both predictive performance tables indicated similar trends of classification performance decreasing as relabel application increased. In some cases coming close to 0.5 ROC area at 100% relabel application, which would refer to random classification output. At 40% relabel application there was comparable results to the data before relabel application, however there was no improvement to it. Anomalies can be seen, especially regarding the test set data. This being caused due to the random distribution of instances throughout folds during cross-validation fold creation.
- R21 - Designing a Programming Language from Scratch
-

Raphael Vigee
Supervised by: Stefan Marr
Project descriptionThis project designed a programming language, from scratch without using any tool (such as Bison, LLVM...) in order to explore all design challenges and performance of a language implementation.
The main emphasis of the project is on performance - or how to run bytecode faster, exploring various areas of optimization, such as enhancing the VM speed by optimizing its C source code, optimizing the number of operations of their behaviour while still maintaining a very “developer friendly” syntax and experience.
Results
The result is a general purpose programming language which has the basic features of a programming language.
It is fully typed and object oriented, running on top of a custom stack-based VM. It supports implicit interfaces and dynamic dispatch. Its syntax and behaviour is very similar to the Go syntax, with some added features coming from various languages, such as C# (ex: operators overloading).
Performance wise, we can compare it to Python as it is a similar technology. There is room for further improvements as the runtime checks are very limited since it is a fully typed language, and a lot of operations could be simplified/optimized at compile time.
Another crucial point was benchmarking to observe potential improvements or regressions in performances, which turned out to be fairly tricky due to the execution time not being constant throughout the execution due to external factors of the environment.
- R22 - From Timed Automata to Timed Programs
-
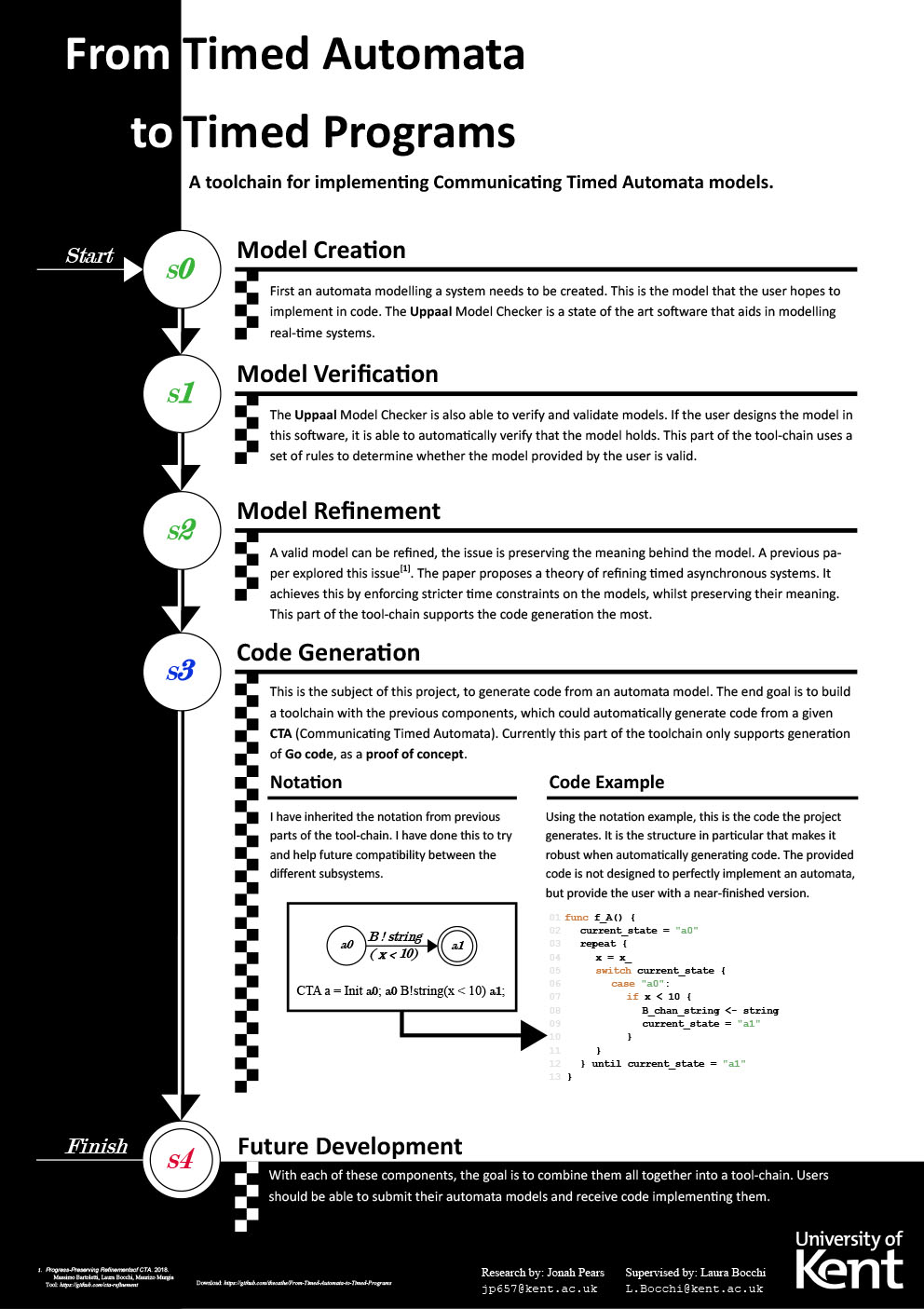
Jonah Pears
Supervised by: Laura Bocchi
Project descriptionCommunicating Timed Automata (CTA) are able to model a group of systems interacting with each other. They are used as theoretical models of asynchronous communications, such as internet protocols. An automaton models all of the branching paths and possible iterations, and, by itself, can describe one aspect of computation. This could be a particular operation, or interaction with another computation or protocol.
Establishing a theoretical model is important when designing a timed asynchronous system. Specifying the constraints and details about how the different components interact with each other is the purpose of modelling these systems. It allows the creator to plan and ensure that everything acts as intended before committing to creating an implementation. Theoretical models are also a powerful design tool as they are able to be verified and simulated. This allows the creator to establish if their design is fit for purpose and not waste time implementing something that wouldn’t work. The current issue is that these models do not help the user in finding an implementation. Once models are proven to be valid, the implementation is not straightforward. It can be difficult to remain faithful to the original model, by preserving its properties and enforcing its constraints.
The goal of this project is to implement a system of generating Go code from an automata model, by mapping and establishing links between the two. I will need to find ways of verifying that the code generated retains the original meaning of the model. One method is by reviewing my code and doing a state by state analysis of how a model handles different input, and comparing this to how the model was expected to act. This also has the possibility of being automated. Another method would be using a model and its complements and seeing whether they retain their relationship in the generated code.
- R23 - Breaches like Mine
-
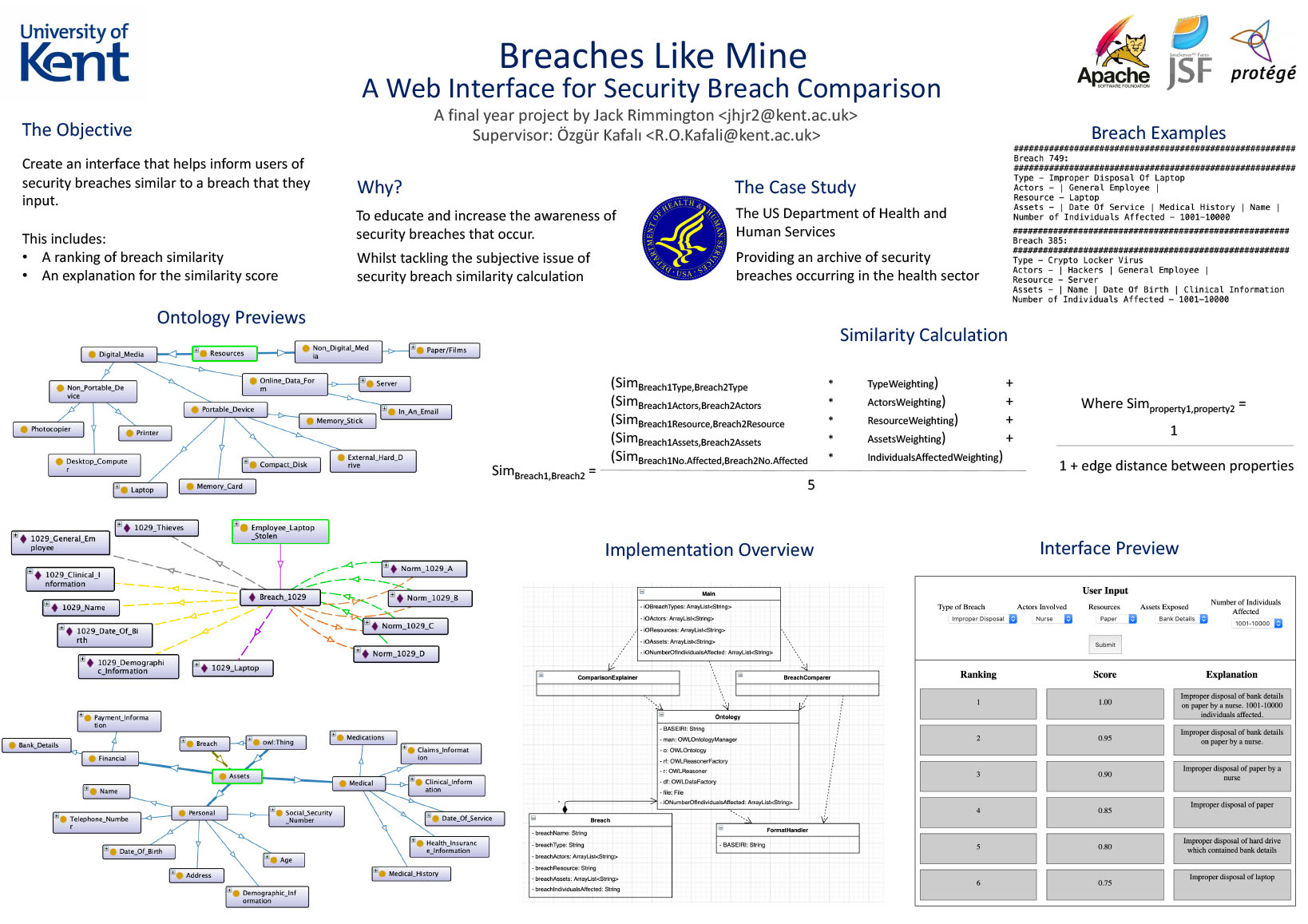
Jack Rimmington
Supervised by: Özgür Kafalı
Project descriptionJudging the similarity between security breaches is a qualitative subjective matter. This project aims to solve this issue by creating an interface which involves a quantitative evaluation of breach similarities. In doing so it forms a user interface to which users can input information on a security breach and find other security breaches which are considered similar. This means that the tool can help inform and raise awareness to users of breaches that exist and the common themes which cause them which might not be obvious to a non-technical user. The Breaches contained in the implementation’s inventory were obtained from the US Department of Health and Human Services. A sample of these were placed into a Protégé ontology. The implementation then obtains these by interacting which the ontology’s owl file using the Owl API. To compare breaches and generate a similarity score, the distance between breach property concepts in the ontology tree was used. Each breach was defined by five breach properties: type, actors, resource, assets and the number of individuals affected. The similarity scores for each of the property concept comparisons were then averaged to give an overall breach similarity. The properties could be given different weightings in the average, in order to try and find the best similarity score generation possible.
Results
Whilst carrying out this project I became more aware of how many breaches occur all the time for simple human error. Most of the security breaches studied involved theft of an unencrypted device that was being used externally, or the improper disposal of a device. The implementation produced, when examined, appears to perform effective security breach comparison, giving breaches that I personally would describe as being similar. The breaches appear to rank as expected and the similarity explanations give useful information on breach commonalities to the user, helping prevent further security breaches. The similarity metric used has shown to be effective. However, as future work, the metric could be tweaked and improved to perhaps give even more accurate similarity scores. The judgement of its effectiveness is, however, subjective. Involvement of experts and their opinions would be of use to give better evaluation.
- R24 - Investigating the Features of Spiking Neurons Applied to Navigation Control
-
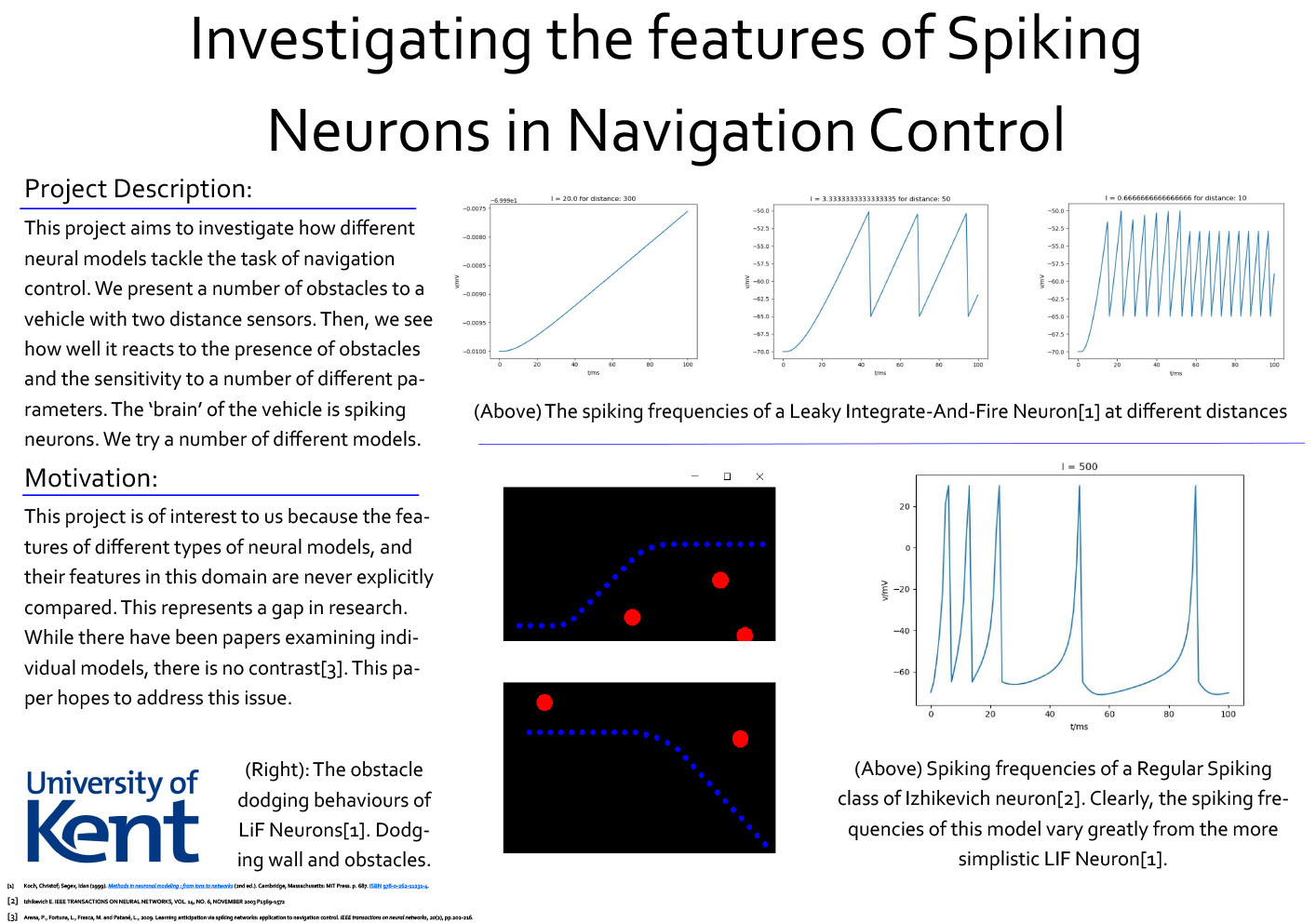
Peter Clapham
Supervised by: Dr Dominique Chu
Project descriptionIn this project I experiment with the features of several neural models in a simple 2D navigation space. I place a vehicle in this 2D space, and a set of obstacles. It has two distance sensors, each with a visible width of 45 degrees positively and negatively from the orientation of the vehicle. These values for distances are fed into the motor neurons, and the spiking frequency over 100ms is taken to be the action of the corresponding motor. This experimentation will give some insight into the characteristics of spiking neurons and conclude which neural models perform best and why. In my investigation, I explore first the Leaky Integrate-And-Fire model. I explore the trajectories it produces with several different parameter configurations. Parameters include the sensitivity to the distance sensors and the transformations on that. Also, further parameters such as the sensitivity of the vehicle to neural outputs is tweaked. Later, the more biologically exact Izhikevich model is used. This has a few different classes, each of which are explored in the project. I am particularly interested in this model as it is designed with cortical neurons in mind. This seems ideal for the task of navigation. All this navigation is done without any prior training, it is simply testing the response of the neurons to the sensory stimulus.
Results
Results show some primitive dodging, where the vehicle will swerve away from obstacles and the boundaries of the arena. Also, the spiking frequency of the neurons are shown to vary greatly. How this translates into navigation behaviours, however, is to be explored. The best representation of results, so far, is the early graph of a LIF Neuron dodging obstacles. It has shown a variety of ways of transforming the input. I settled on an exponentially decaying transformation, such that from about 10 * (width of vehicle) the input is very small, but as it approaches 0 it fires a lot. However, the neurons have shown to be very sensitive to the set parameters. Often, parameter configurations that vary even slightly, can cause the vehicle to not show any intelligent behaviours. A network with more than one motor neuron per input should show better behaviours.
- R25 - The Psychology of Cyber Security
-

Benedict Wagnall
Supervised by: Dr Jason Nurse
Project descriptionIn examining the human element of cybersecurity, researchers and professionals are regularly faced questions such as “why did the user perform action X and not action Y, when action Y is clearly the more security-conscious decision?” or “how did the context of this scenario influence a user into doing Z, something they would never do under regular circumstances?”. Some research has been conducted on this issue, much of which points toward inherent psychological processing errors, known as cognitive biases, as being an emergent factor in understanding user behaviour. The aim of this project is to perform a systematic review on the existing literature relating to the effect of cognitive bias on cybersecurity decisions. The desired outcome of this project is to produce a clear view of the state of the literature, in order to highlight new avenues of research.
Results
Through following and adapting the PRISMA process, a final set of 42 results were obtained. Of these results, 24 were user studies and 18 were theoretical reviews. The majority of the user studies examine optimistic bias, and most of the studies conducted were online or telephone surveys, with only 5 being in-person studies observing a user as they typically interact with a system. Many of the studies, theoretical and study, call for more research and implore system architects and designers to take these biases into account, while very little of the literature is focused on developing methods to avoid cognitive biases. Upon initial investigation, there appears to be a significant imbalance between the attention given to some cognitive biases over others, a lack of meaningful effort into devising methods to overcome cognitive biases, and an over-utilisation of remote questionnaires.
- R26 - Identifying Undesirable Single Sign On Authentications
-
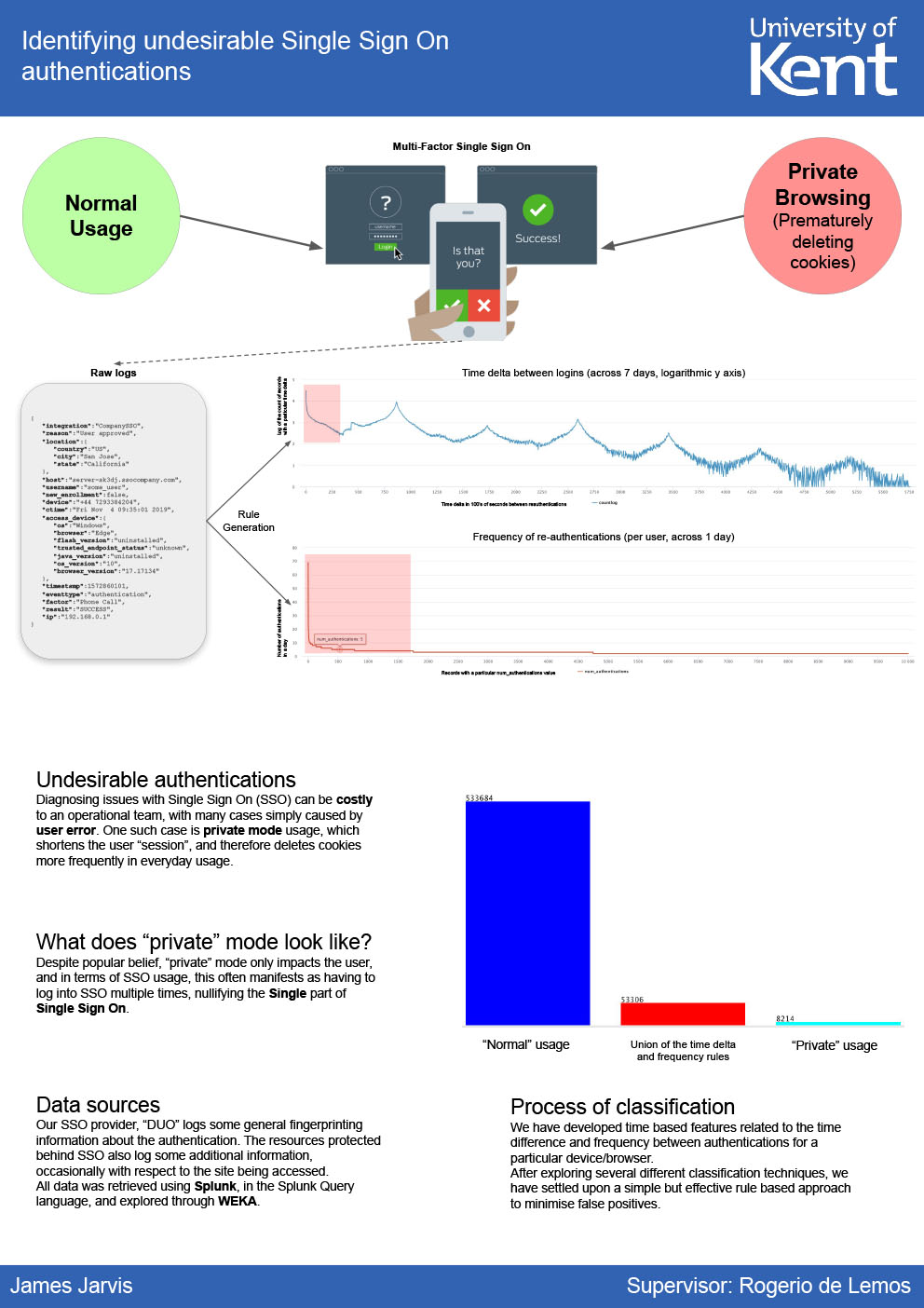
James Jarvis
Supervised by: Rogério de Lemos
Project descriptionSingle Sign On (SSO) provides the benefit of a centralised authentication platform for multiple services, simplifying and increasing the online security for potentially billions of users.
From an operational viewpoint, another benefit is the centralisation of authentication "issues", allowing for a greater audience to be impacted by improvements in support.
One such issue is the mistaken use of a browsers "private mode", which can negatively impact user experience by prematurely deleting user cookies and cause unnecessary support cases to be opened. As a user completes an authentication through SSO, information about the event is logged.
Our work explores the potential of classifying users of "private mode" through these logs. This involves generating several time-based features. Initially supporting our assumptions through a rule based approach, then going on to explore the effectiveness of different algorithms deriving their own models from this data.
Results
Considering the lack of definite "private" indicators from the logs, this work makes a number of assumptions based on the knowledge of the impact private mode has on users, and utilises time based features to classify individual user's behaviour as "normal" or "private".
Given the assumptions made, this work develops a classifier that is consistent with industry assumptions of “private” usage, with ~1% of all authentications being labelled as “private”.
- R27 - Converting PDF Mathematical Formulae to LaTeX
-

Elliot Lake
Supervised by: Simon Thompson
Project descriptionThis project aims to convert mathematics from the PDF file format into LaTeX format. This is in order for a text to speech program to read out these equations to the blind. This operates by reading in all the text from a PDF into a Python 3 UTF-8 String. When this has been completed, all of the words and equations are split into separate strings in their own right. After this, the English words are removed from the list of strings, reducing the string list to equations and other useless aspects of the document, which are then subsequently truncated as well.
In order to make this possible, It was necessary to add a number of algorithms to the Library PDFMiner.six such that the program could recognise and add LaTeX commands to the string so that It could parse Subscripts and superscripts to the program. This was made possible by using Typographical conventions regarding the lines used to position a cursor to print text.
Results
The Neural Network that has been trained with Wikipedia articles to pick up Mathematics and English from a text, is very effective. It will strip out English to such an effect that, in testing on KS2 revision papers, that it will retain the page structure for non-textual aspects such as lines for equations in an implied manner. It also retains most algebraic equations.
However, two problems have emerged with my solution. First of all, there are no means by which the algorithm can pick up dates. Therefore, although the second sweep removes abbreviated month names, the days and the years still remain in a text, without context. In addition, the algorithm doesn’t remove page numbers.
Finally, the algorithm has no means of translating complicated mathematical equations with large square roots or summations into LaTeX as the library PDFMiner.six doesn’t pick these up, and would require similar modifications as I expressed with Superscripts and Subscripts.
- R28 - Smart Insole
-
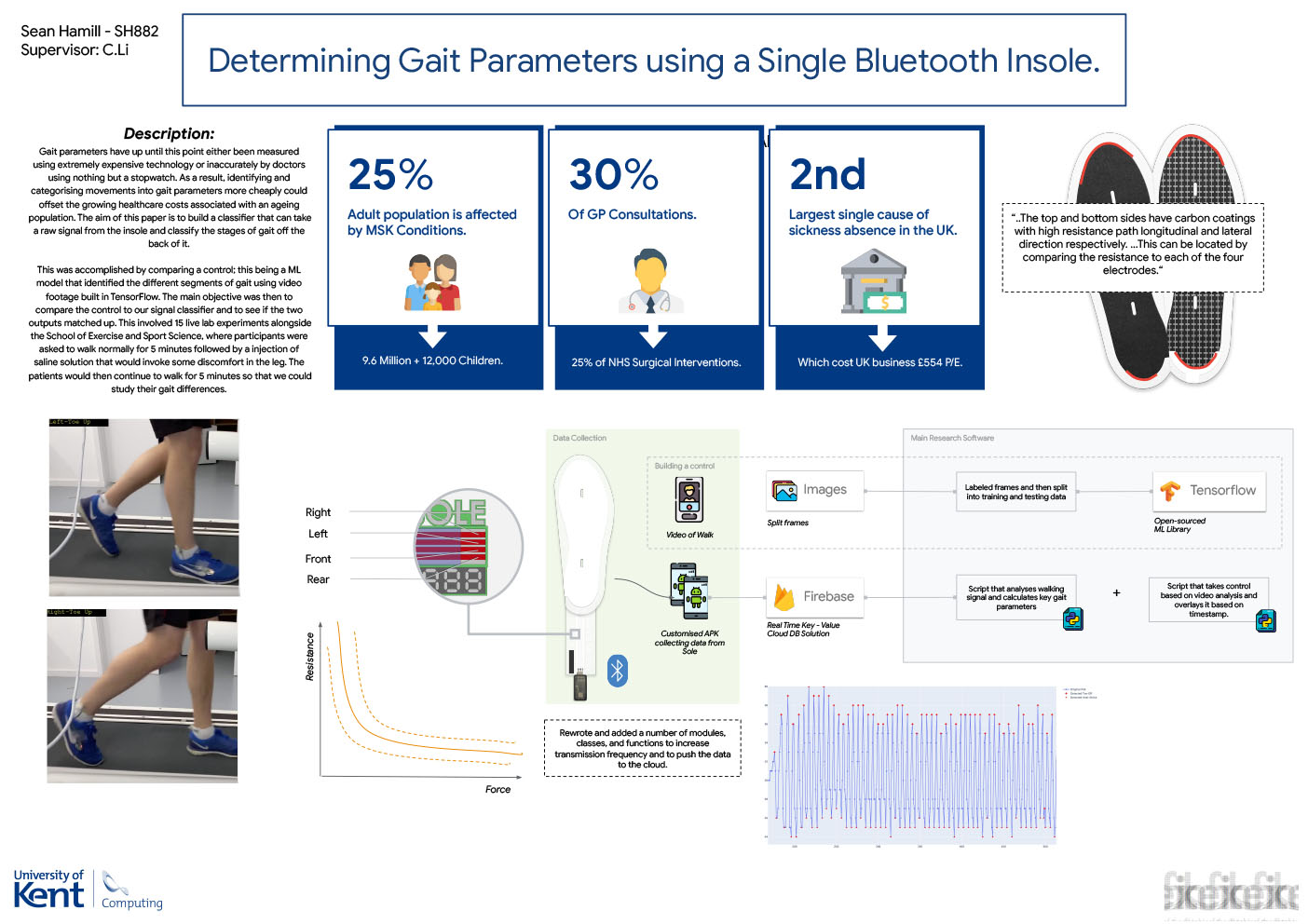
Sean Hamil
Supervised by: Caroline Li
Project descriptionGait parameters have up until this point either been measured using extremely expensive technology or inaccurately by doctors using nothing but a stopwatch. As a result, identifying and categorising movements into gait parameters more cheaply could offset the growing healthcare costs associated with an ageing population. The aim of this paper is to build a classifier that can take a raw signal from the insole and classify the stages of gait off the back of it.
This was accomplished by comparing a control; this being a ML model that identified the different segments of gait using video footage built in TensorFlow. The main objective was then to compare the control to our signal classifier and to see if the two outputs matched up. This involved 15 live lab experiments alongside the School of Exercise and Sport Science, where participants were asked to walk normally for 5 minutes followed by an injection of saline solution that would invoke some discomfort in the leg. The patients would then continue to walk for 5 minutes so that we could study their gait differences.
- R29 - Digital Bullet Journal (BuJo) : Journaling for Mental Health Tracking
-

Snowy Jackson
Supervised by: Anna Jordanous
Project descriptionThis project aims to show that digital journaling is beneficial for long term health and mental health management by taking the main principles of the Bullet Journal phenomena and creating a digital counterpart that easily and efficiently allows people to gain a greater understanding of their psyche and familiarise themselves with aspects of their daily life they don’t usually ponder. The data reported by the person creates a digital image of themselves, thus allowing them (and if they wish, their health team) to analyse their habits, thoughts, symptoms and reactions to better their lives and health.
To achieve this, Digi-BujoBot was created to utilise phone habits and use gamification to allow users to track and record their health, thoughts, symptoms and moods in a meaningful and creative way to encourage greater understanding of the self and thus be able to make well thought out decisions to improve their quality of life.
- R30 - (Data) Mining with Lasers
-
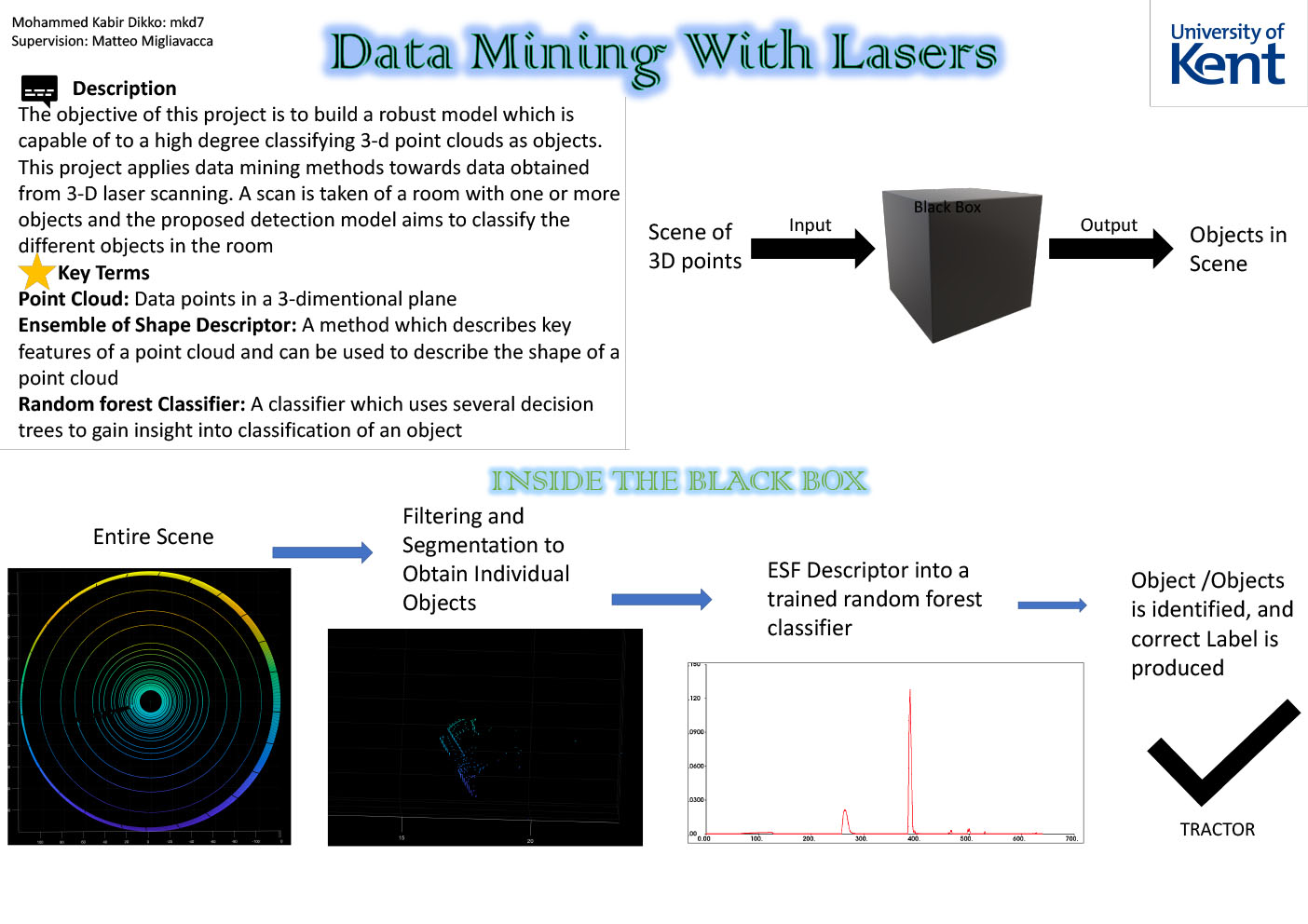
Mohammed Dikko
Matteo Migliavacca
Project descriptionPoint clouds are important geometric data obtained from a variety of 3D sensors.
Recognizing objects from point clouds has several benefits and real-life applications.
However, point cloud processing can also come with several disadvantages and challenges.
Such challenges include classification and identification of objects in various scenes. In this context this paper aims to address the object classification of 3-d cloud-points obtained from a Lidar sensor. The objective is to effectively classify a variety of objects individually as well as in scenes.
To accomplish this task, the various scenes underwent various segmentation and filtering methods to obtain individual object point clouds. Features of the objects were generated using the Ensemble of Shape function which computes shape functions describing the nature of the point cloud. These features or descriptors were then passed to a random forest classifier which was trained on other descriptors so as to with high certainty predict what an object is and output a label.